Redes de computadores volume 2
1 gostou•4,395 visualizações

Este documento apresenta um capítulo sobre a camada de transporte no modelo TCP/IP. Ele descreve as principais responsabilidades da camada de transporte, como fornecer comunicação entre processos de aplicação e controlar fluxo e congestionamento. Além disso, explica como a multiplexação e demultiplexação na camada de transporte permitem que múltiplos processos se comuniquem através da mesma interface de rede.

























































Redes de computadores volume 2
- 1. UNIVERSIDADE FEDERAL RURAL DE PERNAMBUCO (UFRPE) UNIDADE ACADÊMICA DE EDUCAÇÃO A DISTÂNCIA E TECNOLOGIA Redes de Computadores Juliano Bandeira Lima Obionor Nóbrega Volume 2 Recife, 2011
- 2. Universidade Federal Rural de Pernambuco Reitor: Prof. Valmar Corrêa de Andrade Vice-Reitor: Prof. Reginaldo Barros Pró-Reitor de Administração: Prof. Francisco Fernando Ramos Carvalho Pró-Reitor de Extensão: Prof. Paulo Donizeti Siepierski Pró-Reitor de Pesquisa e Pós-Graduação: Prof. Fernando José Freire Pró-Reitor de Planejamento: Prof. Rinaldo Luiz Caraciolo Ferreira Pró-Reitora de Ensino de Graduação: Profª. Maria José de Sena Coordenação Geral de Ensino a Distância: Profª Marizete Silva Santos Produção Gráfica e Editorial Capa e Editoração: Rafael Lira, Italo Amorim e Arlinda Torres Revisão Ortográfica: Elias Vieira Ilustrações: Moisés de Souza Coordenação de Produção: Marizete Silva Santos
- 3. Sumário Apresentação.................................................................................................................. 4 Conhecendo o Volume 2................................................................................................. 5 Capítulo 1 – A Camada de Transporte.............................................................................. 6 1.1 Introdução..................................................................................................................6 1.2 Multiplexação e demultiplexação na camada de transporte......................................8 1.3 UDP – Protocolo de Datagrama do Usuário..............................................................10 1.4 TCP – Protocolo de Controle de Transmissão...........................................................12 1.5 TCP e UDP: Tópicos Adicionais..................................................................................21 Capítulo 2 – A Camada de Rede e o Protocolo IP........................................................... 29 2.1 Introdução................................................................................................................29 2.2 Algoritmos de roteamento.......................................................................................35 2.3 A Camada de Rede na Internet.................................................................................42 Capítulo 3 – Internet, Intranet e Extranet...................................................................... 55 3.1 Internet.....................................................................................................................55 3.2 Intranet.....................................................................................................................56 3.3 Extranet....................................................................................................................58 Considerações Finais..................................................................................................... 62 Conheça os Autores...................................................................................................... 63
- 4. Apresentação Caro(a) aluno(a), Seja bem-vindo(a) ao curso de Redes de Computadores. Este curso é composto por 4 volumes. Neste primeiro volume, vamos estudar os conceitos introdutórios e os principais modelos de referência na área Redes de Computadores. Também estudaremos, neste volume, as principais aplicações utilizadas em ambiente de Internet (como, por exemplo, navegação na Web, correio eletrônico, telefonia via Internet, dentre outros). No segundo volume, serão abordados os protocolos que fazem transporte de informações em uma rede. Um outro assunto que será abordado é a identificação e localização de computadores em um ambiente de Rede. No terceiro volume, você aprenderá sobre como os dados são enviados através dos meios físicos de comunicação com e sem fio. Por fim, o quarto e último volume abordará tópicos de gerenciamento e segurança de redes de computadores. Concluindo a nossa disciplina, apresentaremos conceitos sobre a Próxima Geração de Redes de Computadores. Bons estudos! Juliano Bandeira Lima e Obionor O. Nóbrega Professores Autores 4
- 5. Redes de Computadores Conhecendo o Volume 2 Módulo 2 – O Protocolo TCP/IP e a Internet Carga Horária: 15 h/aula Objetivo: Introduzir os principais conceitos relacionados à camada de transporte e à camada de rede, apresentando seus protocolos básicos e descrevendo suas funcionalidades. Conceituar Internet, Intranet e Extranet, relacionando a sua importância nos diversos cenários das redes de computadores. Conteúdo Programático » Camada de Transporte; » Camada de Rede; » Internet, Intranet e Extranet. 5
- 6. Redes de Computadores Capítulo 1 – A Camada de Transporte Vamos conversar sobre o assunto? Caro(a) aluno(a), No volume 1, você teve a oportunidade de conhecer importantes conceitos relacionados às redes de computadores. Ao longo da sua apresentação a este mundo cheio de novidades, você estudou aspectos como topologia e classificação de redes, meios físicos e técnicas de comutação. Você pôde perceber, também, a importância do uso de modelos de camadas para descrever e estudar as redes de computadores. Considerando de maneira particular este último tópico, podemos iniciar nossa conversa levantando um simples questionamento: por que o modelo TCP/IP recebeu este nome? Por que não recebeu, por exemplo, o nome HTTP/FTP, como referência a dois dos protocolos que conhecemos na camada de aplicação? Bom, a respota à pergunta feita guarda uma relação com as duas camadas que, neste capítulo, começaremos a estudar: a camada de transporte e a camada de rede. Alguns autores mencionam que, sem as funções desempenhadas por essas camadas, o conceito de protocolos em camadas não faria qualquer sentido. Naturalmente, esta é uma afirmação que só será compreendida de forma completa quando voltarmos nossa atenção para as próximas páginas e descobrirmos os detalhes que a justificam. Por enquanto, é suficiente que mantenhamos acesa a vontade de conhecer cada vez mais sobre as redes de computadores e que, em nossa memória, estejam presentes os conceitos aprendidos nos tópicos estudados enteriormente. Assim, será mais fácil reunir as informações e perceber a interdependência que existe entre os diversos assuntos dessa disciplina. Vamos em frente! 1.1 Introdução Ao longo dos nossos estudos sobre a camada de aplicação, realizados no volume 1 desta disciplina, algumas “manchetes” sobre a camada de transporte já foram publicadas. Neste capítulo, entretanto, conheceremos de forma mais minuciosa certos aspectos que concedem a esta camada o status de núcleo de toda a hierarquia de protocolos. Para começar, podemos descrever as três responsabilidades básicas da camada de transporte. A primeira delas depende, fundamentalmente, da relação entre esta camada e a camada de rede. Quando, num sistema de origem (um computador pessoal que temos em casa, por exemplo), monta-se um datagrama, os algoritmos e protocolos da camada de rede devem se encarregar de encaminhá-lo até o sistema de destino (um servidor no qual estejamos buscando uma página, por exemplo). No entanto, é de responsabilidade da camada de transporte ampliar este serviço e fazer com que a comunicação aconteça, não entre os sistemas simplesmente, mas entre dois processos das camadas de aplicação que rodam nesses sistemas finais. A segunda responsabilidade da camada de transporte tem a ver com a heterogeneidade que se pode encontrar nos níveis mais baixos de uma pilha de protocolos. Sinais transmitidos por meio de fibras ópticas, por exemplo, estão menos propensos à ação de ruído do que aqueles transmitidos por cabos metálicos ou num meio físico sem fio; nas camadas de enlace e na de rede, protocolos com características bem distintas podem ser 6
- 7. Redes de Computadores utilizados. Tudo isso tem impacto sobre o desempenho de uma comunicação, mas, a camada de transporte possui a atribuição de fazer com que duas entidades possam se comunicar de maneira confiável, independentemente dos cenários implementados na chamada subrede. O terceiro desafio enfrentado pela camada de transporte diz respeito aos controles de congestionamento e de fluxo. A taxa em que um processo da camada de aplicação de um host produz dados a serem entregues às camadas inferiores e, posteriormente, enviados nem sempre é comportada pelos recursos disponíveis na rede. Se o envio de pacotes for feito sem qualquer preocupação, podem-se formar filas nas entradas dos roteadores e, consequentemente, haver descartes de dados. Essa é uma situação de congestionamento. De outra forma, mesmo que os enlaces e equipamentos da subrede sejam capazes de lidar com a injeção de pacotes num ritmo acelerado, o sistema de destino pode não ser suficientemente robusto para isso, isto é, não ter a capacidade de processar os dados na velocidade em que a rede os entrega. Neste caso, estamos diante de um problema de fluxo, algo cujo controle também se deve à camada de transporte. A fim de cumprir com as responsabilidades descritas, a camada de transporte estabelece uma comunicação lógica entre processos de aplicação que rodam em hosts diferentes. Isso significa que, para uma aplicação, é como se dois computadores que se comunicam estivessem diretamente ligados, mesmo que, na realidade, existam entre eles dezenas de roteadores e tipos bem distintos de enlaces. Esta ideia pode ser melhor compreendida se observarmos a Figura 1.1. Nesta ilustração, vê-se que, nos equipamentos da subrede (roteadores), acessa-se apenas até a camada 3, o que é suficiente para o desempenho da tarefa básica desses equipamentos (determinação do percurso a ser seguido pelos datagramas). Os dados referentes à camada de transporte, que, na terminologia da Internet, são denominados segmentos, são encapsulados e desencapsulados apenas nos sistemas finais; o mesmo acontece com as mensagens recebidas de um processo de aplicação do sistema de origem e entregues a outro processo de aplicação no sistema de destino. Figura 1.1 – Comunicação lógica provida pela camada de transporte Por meio dessa comunicação lógica entre processos, diversos serviços são oferecidos pelas entidades de transporte (hardware/software que executam o trabalho). Nesse contexto, os serviços orientados a conexão possuem destacada importância. Com eles, uma entidade remetente estabelece uma espécie de contato com a entidade de 7
- 8. Redes de Computadores destino, para se certificar de que ela está lá, aguardando a chegada dos dados que só depois serão enviados. Isso é necessário sempre que, nos níveis inferiores da rede, estiverem trabalhando protocolos que simplesmente injetam os dados nos enlaces, sem saber se, no outro extremo, existe “alguém” os aguardando. Os serviços com confirmação também são de grande importância. Por meio deles, entidades de transporte que se comunicam trocam dados para informar se um segmento específico foi entregue com sucesso. Quando isso não acontece, ações como a de reenvio de segmentos podem ser executadas. A lista a seguir resume algumas das propriedades comuns que se espera que um protocolo de transporte ofereça: » Garantia de entrega da mensagem; » Entrega de mensagens na mesma ordem em que foram enviadas; » Entrega de, no máximo, uma cópia de cada mensagem; » Admissão de mensagens arbitrariamente grandes; » Implementação de controle de fluxo entre o transmissor e o receptor; » Concentração dos vários processos de aplicação existentes em cada host. Apesar de boa parte dos processos de aplicação requisitar serviços orientados a conexão e com garantias de entrega (o que não se consegue com a camada de rede), há situações em que serviços sem conexão e não confiáveis são necessários. Considere, por exemplo, uma situação em que se deseja assistir um vídeo pela Internet. Você já imaginou se, a cada quadro de vídeo recebido, nosso computador tivesse que enviar uma informação ao remetente, confirmando a entrega, para só então ele injetar um novo quadro na rede? A sensação de movimento do filme seria completamente perdida. Por outro lado, se nossa máquina deixar de receber ou receber com erro um ou outro quadro, dentre os 30 quadros que recebemos por segundo, talvez o prejuízo não seja tanto. Na Internet, essa questão é administrada pelo uso de dois protocolos na camada de transporte: o UDP (User Datagram Protocol, Protocolo de Datagrama de Usuário), que provê à aplicação solicitante um serviço não confiável e não orientado a conexão, e o TCP (Transmission Control Protocol, Protocolo de Controle de Transmissão), que provê à aplicação solicitante um serviço confiável e orientado a conexão. O projetista de uma aplicação de rede deve especificar o protocolo de transporte a ser usado. Aprenderemos mais sobre o UDP e o TCP noutras seções. 1.2 Multiplexação e demultiplexação na camada de transporte Na seção introdutória deste capítulo, colocamos como a primeira responsabilidade de uma camada de transporte a ampliação do serviço de entrega desempenhado pela camada de rede. Esta tarefa é necessária porque, sobre uma única interface de rede por meio da qual um host se comunique, diversos processos de aplicação podem estar em execução. Para explicar melhor, consideremos uma situação em que estejamos, simultaneamente, acessando uma página da Internet, enviando um arquivo via FTP e mandando um e-mail, o que envolve 3 processos de aplicação. Os dados que são gerados por essas aplicações, ao serem repassados para as camadas inferiores, devem possuir um único identificador de rede, visto que estão relacionados ao mesmo sistema de origem. Até aí, tudo bem... mas quando precisarmos receber de volta esses dados da camada de rede (ou entregálos nos respectivos destinos), como saberemos para que processo de aplicação cada um deve seguir? É por este motivo que existem os sockets, que são portas pelas quais os dados passam da rede para o processo e do processo para a rede. 8
- 9. Redes de Computadores Quando os dados vindos de uma aplicação chegam à camada de transporte, eles trazem consigo um número de porta específico, que indica o seu processo de origem. Este número é, então, escrito em determinado campo do segmento de camada de transporte a ser montado. No segmento, também se escreve o número da porta de destino, que indica o processo ao qual se deve entregar os dados do outro lado da conexão. Só depois desse procedimento é que se faz o repasse dos dados à camada de rede. Fazendo uma simples analogia, é como se desejássemos enviar uma carta a alguém que morasse num edifício. Se escrevêssemos no envelope apenas o número do prédio, o mensageiro não saberia para quem encaminhar a correspondência. O número de porta funciona como o número do apartamento, permitindo o passo final da entrega. A reunião de dados provenientes de diferentes processos, aos quais diferentes números de portas são atribuídos, e seu repasse à camada de rede é denominada multiplexação; a recepção, por meio de uma interface de rede, de um grupo de dados e sua entrega a diferentes processos de aplicaçao é denominada demultiplexação. A multiplexação e a demultiplexação na camada de transporte são ilustradas na Figura 1.2. Figura 1.2 – Multiplexação e demultiplexação na camada de transporte Na camada de transporte da Internet, cada um dos campos reservados aos números de portas, presentes tanto no UDP quanto no TCP, possuem 16 bits (números decimais de 0 a 65535). Os números de porta entre 0 e 1023 são denominados números de porta bem conhecidos, estando reservados a protocolos cuja utilização é ampla, como o HTTP (porta de número 80) e o FTP (porta de número 21). A lista completa dos números de porta bem conhecidos pode ser encontrada na RFC 1700 e na RFC 3232, em http://www.iana.org. Como nem todos os protocolos de aplicação possuem números de porta bem conhecidos, outras estratégias são necessárias para prover a multiplexação/ demultiplexação. Uma primeira opção é empregar um servidor de processos, que atua num esquema conhecido como protocolo de conexão inicial. Este servidor atende a uma série de portas ao mesmo tempo, aguardando uma solicitação de conexão. Quando uma solicitação a qual nenhum servidor está associado é recebida, o servidor de processos gera uma conexão para o servidor solicitado, funcionando como uma espécie de proxy (intermediário). Noutro modelo, emprega-se um processo especial chamado servidor de nomes, que mantém um registro com os nomes dos diversos serviços e seus respectivos números de porta. As solicitações recebidas e que contêm, inicialmente, o nome do serviço que desejam são, então, encaminhadas para este servidor, o qual retorna o número de porta após uma consulta no registro. Depois disso, a conexão com o servidor de nomes é encerrada e uma nova conexão com o serviço desejado é estabelecida. 9
- 10. Redes de Computadores Você Sabia? Firewall é o nome dado ao dispositivo de uma rede de computadores que tem por objetivo aplicar uma política de segurança a um determinado ponto de controle da rede? Algumas das ações mais importantes de um firewall têm efeito por meio do bloqueio ou da restrição do estabelecimento de conexões de certas portas da camada de transporte. Aprenderemos mais sobre firewalls quando tratarmos de segurança em redes de computadores. 1.3 UDP – Protocolo de Datagrama do Usuário Nesta seção, começaremos nossos estudos sobre os protocolos que atuam na camada de transporte da Internet. O primeiro protocolo a ser examinado é o UDP e a sua principal característica é a de não ser orientado a conexão. O UDP não se preocupa em estabelecer um contato inicial com a entidade a quem os dados serão enviados, não sendo, portanto, capaz de oferecer qualquer tipo de garantia de que uma entrega bem sucedida será efetuada. Diante disso, resta a este protocolo a funcionalidade básica que descrevemos na seção anterior: multiplexar e demultiplexar dados, para fins de intermediação entre os diversos processos de aplicação e a interface de rede. Diante da sua simplicidade, a importância do UDP enquanto protocolo de transporte poderia até ser questionada... isso sugere a apresentação de alguns motivos que indicam a sua relevância em certos cenários e diante de necessidades específicas. Quando o TCP é empregado na camada de transporte, antes de repassar os dados vindos dos processos de aplicação à camada de rede, uma série de verificações é realizada. O protocolo precisa verificar, por exemplo, se a entidade de destino possui espaço suficiente para acomodar novos dados (controle de fluxo); além disso, é necessário verificar se confirmações de entrega de segmentos anteriormente enviados já foram recebidas. Em caso negativo, pode-se priorizar o reenvio de dados antigos, em vez de injetar na rede dados mais recentes. Com o UDP, nada disso acontece. Tão logo um processo de aplicação passe dados à entidade de transporte, o UDP ele os empacotará num segmento e os repassará imediatamente à camada de rede. Essa forma de proceder tem grande utilidade em aplicações que requerem o que chamamos de tempo real, como uma videoconferência ou uma chamada de voz pela Internet. Em situações como essas, minimizar o tempo decorrido entre a criação dos dados no lado do transmissor e a sua entrega no destino é a prioridade. O alcance desse objetivo seria fortemente comprometido, caso empregássemos o TCP e tivéssemos aguardar verificações como as que descrevemos. O não estabelecimento de conexões por parte do UDP também traz benefícios a aplicações como o DNS. O que o DNS faz se resume a uma simples consulta a um banco de dados; se este banco, por algum motivo, não responder, o solicitante pode refazer a consulta sem grandes prejuízos. Nesse contexto, ao dispensar toda uma troca inicial de informações de configuração de conexão, o UDP acelera o envio de pedidos e respostas, evitando uma lentidão desnecessária. Uma outra consequência disso é o fato de, no UDP, não ser preciso manter estados de conexão, que incluem buffers de envio e recebimento, parâmetros de controle de congestionamento e parâmetros numéricos de sequência e de reconhecimento (quando estudarmos o TCP, entenderemos melhor tudo isso). Como esses parâmetros não precisam ser monitorados, um servidor dedicado a uma aplicação específica pode suportar um número muito maior de clientes ativos quando a aplicação roda sobre UDP. Por fim, no UDP, temos uma sobrecarga de cabeçalho de pacote menor: apenas 8 bytes, em troca de 20 10
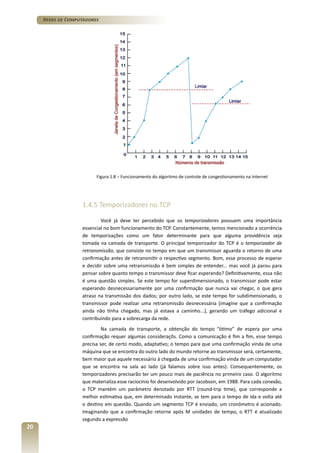
- 11. Redes de Computadores bytes do TCP. A Figura 1.3 apresenta um quadro relacionando aplicações conhecidas e o protocolo de transporte utilizado por cada uma delas. Como era de se esperar, aplicações como o correio eletrônico, o acesso a um terminal remoto e a Web, que requerem certas garantias de entrega, utilizam o TCP. No gerenciamento de uma rede, o UDP é preferível; é comum que tarefas de gerenciamento sejam executadas em momentos em que a rede já está com algum tipo de sobrecarga, o que dificulta a transferência confiável de dados com congestionamento controlado. Como já foi comentado, as aplicações que envolvem multimídia utilizam, normalmente, o UDP. Todavia, em muitos casos, tem-se empregado o TCP, para evitar, por exemplo, situações em que muitos remetentes enviem pacotes “indiscriminadamente”, sem que a rede tome qualquer atitude. É importante mencionar, ainda, que o uso do UDP permite que a confiabilidade da transferência dos dados esteja embutida na própria aplicação. Protocolo de camada de Protocolo de transporte aplicação subjacente Correio eletrônico SMTP TCP Acesso a terminal remoto Telnet TCP Web HTTP TCP Transferência de arquivo FTP TCP Servidor remoto de arquivo NFS Tipicamente UDP Recepção de multimídia Tipicamente proprietária UDP ou TCP Telefonia pela Internet Tipicamente proprietária UDP ou TCP Gerenciamento de rede SNMP Tipicamente UDP Protocolo de roteamento RIP Tipicamente UDP Tradução de nome DNS Tipicamente UDP Aplicação Figura 1.3 – Algumas aplicações da Internet e seus protocolos de transporte subjacentes Na Figura 1.4, é apresentada a estrutura de um segmento UDP. Conforme já tínhamos comentado, além do campo de dados da aplicação, o segmento UDP contém um cabeçalho bastante simples, com apenas quatro informações que perfazem um total de 8 bytes. Na primeira linha, observamos os campos porta de origem e porta de destino, que têm a função de orientar os procedimentos de multiplexação e de demultiplexação descritos na seção anterior. O número da porta de origem é particularmente importante quando uma resposta deve ser devolvida à origem (o processo que transmite a resposta copia o campo porta de origem do segmento de entrada no campo porta de destino no segmento de saída, especificando qual processo na máquina transmissora deve recebê-lo). O campo comprimento especifica o tamanho total do segmento, incluindo o cabeçalho, e o campo soma de verificação serve para detectar erros. O valor do campo soma de verificação auxilia uma espécie de “prova dos 9”, que envolve os dados presentes no segmento e que é executada na sua entrega. Se, por meio desse procedimento, for 11
- 12. Redes de Computadores identificado um erro (proveniente, por exemplo, de alguma imperfeição ao longo da transmissão em camadas inferiores), o segmento será simplesmente descartado ou será repassado à camada de aplicação com algum aviso de alerta (o UDP não realiza a correção de um erro detectado). É importante que se tenha esse mecanismo de controle de erros fim a fim, mesmo no UDP, porque não há garantia de que todos os enlaces entre a origem e o destino forneçam verificação de erros (lembremos que o que acontece na camada de transporte deve ser, de certo modo, independente do que acontece nas camadas inferiores). Figura 1.4 – Estrutura do segmento UDP 1.4 TCP – Protocolo de Controle de Transmissão O TCP é um protocolo projetado para oferecer um fluxo de bytes fim a fim sobre uma rede possivelmente heterogênea e não-confiável. Quando mencionamos a heterogeneidade da rede, estamos nos referindo à possibilidade de, nas camadas inferiores à de transporte, termos, na prática, um “emaranhado” de redes com topologias, larguras de banda, tamanhos máximos de pacotes e retardos bem diferentes. Os protocolos que lidam com essa diversidade não oferecem a garantia de que os dados são entregues na ordem em que são enviados, por exemplo; na verdade, muitos deles não oferecem sequer a garantia de que os dados são entregues (ainda que fora de ordem). O TCP vem para cobrir essas “brechas”, sendo representado por uma entidade de transporte que pode ser um procedimento de biblioteca, um processo do usuário ou parte do núcleo numa máquina. Com o TCP, estabelecem-se conexões lógicas full-duplex entre processos que estão sendo executados sobre dois computadores quaisquer da Internet. Isso significa que, antes do envio dos dados úteis, é necessária uma fase de estabelecimento de conexão explícita, de modo análogo ao que ocorre numa chamada telefônica usual, por exemplo. Também se faz necessária uma fase para que a conexão seja encerrada. Este protocolo precisa, ainda, se adaptar à comunicação entre dois computadores que estão bem distantes um do outro, bem como à comunicação entre máquinas que se encontram numa mesma sala. A diferença básica entre estes dois cenários é que os tempos para que os dados enviados por um dos lados vão até a outra a extremidade e retornem (RTT, round-trip time) podem variar bastante. Veremos que o RTT é uma variável crítica para que o serviço de confirmação oferecido pelo TCP funcione corretamente. 12 Outro aspecto que o TCP considera é a entrega em ordem dos dados. As redes sobre as quais uma camada de transporte é implementada podem ser bastante dinâmicas do ponto de vista de encaminhamento dos dados. Isso acontece porque os algoritmos de roteamento, sobre os quais falaremos no próximo capítulo, buscam direcionar os datagramas por linhas que apresentam custos menores (em relação ao retardo, à distância geográfica a ser percorrida, ao congestionamento a ser enfrentado etc). O fato é que esses custos podem ser modificados com o passar do tempo e datagramas com origem e destino
- 13. Redes de Computadores iguais podem seguir rotas distintas, sendo entregues fora de ordem. O TCP recorre, então, a números de sequência e faz com que, em alguns casos, a entidade de transporte de destino fique aguardando a chegada de um segmento mais antigo, para que os dados recebidos possam ser repassados à camada de aplicação na ordem correta, sem a presença “lacunas”. Uma última funcionalidade a ser abordada nesta introdução ao TCP é a de controle de fluxo fim a fim, a qual se baseia no emprego de buffers ou janelas (mais tarde, entenderemos o porquê de se utilizar este termo). Um buffer é uma espécie de área de armazenamento de dados presente nas entidades de transporte transmissoras e receptoras. No transmissor, buffers são necessários para armazenar dados cuja entrega ainda não foi confirmada. Caso seja necessária uma retransmissão, os dados estarão lá, seguramente guardados. No receptor, os buffers armazenam dados que estão esperando “pedaços” mais antigos que ainda não chegaram ou dados que estão simplesmente aguardando o repasse a um processo da camada de aplicação (costuma-se dizer que um processo de aplicação, no momento apropriado, lê dados que estão armazenados num buffer da camada de transporte). Pela ação do controle de fluxo fim a fim, sob condições normais de funcionamento, uma entidade transmissora não pode enviar uma quantidade de segmentos que não caiba na área de armazenamento da entidade receptora. Para isso, juntamente com a confirmação de entrega de um segmento, a entidade de transporte receptora envia à origem um aviso, informando a sua disponibilidade de buffers (ou o tamanho da sua janela). Naturalmente, o controle de fluxo deve observar, também, questões de congestionamento. Não adiantaria termos, por exemplo, dois computadores com grande capacidade de processamento e com janelas grandes se comunicando por uma rede lenta; as limitações de velocidade da rede teriam que ser respeitadas. Algo semelhante aconteceria se tivéssemos dois computadores lentos se comunicando por enlaces de grande velocidade. 1.4.1 O segmento TCP Como já mencionamos, o nome dado a um pacote trocado entre duas entidades de transporte TCP é segmento. Cada segmento possui um campo de dados, no qual uma certa quantidade de bytes recebidos do processo transmissor é agrupado. Além disso, um segmento TCP possui um cabeçalho como o que é ilustrado na Figura 1.5. Figura 1.4 – Estrutura do segmento TCP Os campos porta de origem e porta de destino possuem a finalidade já descrita no estudo do UDP. Juntamente com os endereços das interfaces de rede de origem e destino, esses campos identificam de forma exclusiva uma conexão TCP. Os campos número de sequência, número de confirmação e janela estão envolvidos em algumas das funções que mencionamos (prevenção contra entrega de duplicatas, conformação de entrega, controle de fluxo etc). O número de sequência, especificamente, contém a numeração associada ao 13
- 14. Redes de Computadores primeiro byte de dados transportado no segmento. Os campos URG a FIN são todos flags (sinalizadores). SYN e FIN são usados, respectivamente, no estabelecimento e no término de uma conexão. ACK é ativado quando o campo número de confirmação tiver que ser considerado. URG é ativado quando o segmento contém dados urgentes (o campo ponteiro de urgência indica onde começam os dados não urgentes contidos no segmento). A ativação de PSH indica que o receptor deve entregar os dados à aplicação mediante sua chegada, em vez de armazená-los até que um buffer completo tenha sido recebido. RST é utilizado para reiniciliar uma conexão que tenha ficado confusa por algum motivo. O campo soma de verificação funciona como no UDP e o campo opções serve para o oferecimento de recursos extras, não previstos pelo cabeçalho comum. Nas opções, um host pode, por exemplo, estipular o máximo de carga útil do TCP que está disposto a receber. 1.4.2 Estabelecimento e encerramento de conexões Para explicarmos como uma conexão é estabelecida no TCP, consideraremos que um dos lados, o host 1, desempenha o papel de chamador ou de cliente (entidade que toma a iniciativa para o estabelecimento da conexão) e que o outro lado, o host 2, desempenha a função de chamado ou de servidor (participante passivo). O algoritmo que determina os passos que devem ser seguidos para que a conexão seja estabelecida é denominado handshake de três vias (veja a Figura 1.5). Figura 1.5 – Handshake de três vias: estabelecimento de uma conexão TCP (1) Inicialmente, o cliente envia ao servidor um segmento contendo o número de sequência incial que ele pretende usar. O flag SYN deve estar ativado, indicando uma ação para estabelecimento de conexão. O campo número de sequência do segmento carrega o valor x. (2) O servidor responde com um segmento em que, além do SYN, está ativado, também, o flag ACK, indicando que o campo número de confirmação, ao qual se atribui o valor x + 1, contém uma confirmação relacionada ao segmento recebido (o valor atribuído é x + 1 para informar ao outro lado o número de sequência do próximo segmento que o servidor espera receber; noutras palavras, o servidor indica que todos os segmentos com números de sequências iguais ou menores a x já foram recebidos). (3) Finalmente, o cliente responde com um terceiro segmento que confirma o número de sequência do servidor e, a partir de então, os dados úteis podem fluir de um lado a outro. Os critérios para a escolha dos números de sequência iniciais dos segmentos trocados numa conexão TCP não serão tratados em detalhes neste material. No entanto, 14
- 15. Redes de Computadores é suficiente dizermos que as numerações de cada lado são determinadas de maneira a evitar que um mesmo número de sequência seja reutilizado com frequência. Se isso acontecesse, o TCP teria mais dificuldade para rejeitar segmentos duplicados ou entregues fora de ordem. Outro detalhe importante no estabelecimento de conexões no TCP tem a ver com o uso de timers ou temporizadores (estudaremos isso mais à frente). Sempre que um cliente envia um segmento na tentativa de iniciar uma conexão, ele ativa um timer e aguarda o retorno do servidor por um certo tempo. Se este retorno não acontecer, o cliente entende que o segmento inicial se perdeu e realiza um novo pedido. Juntamente com os números de sequência, são os timers que asseguram que não haverá confusão durante o estabelecimento de uma conexão. Dica Na página http://www.netbook.cs.purdue.edu/animations/TCP%203-way%20handshake.html, encontra-se uma animação em flash que ilustra o estabelecimento de uma conexão por meio do handshake de três vias. Acesse! No TCP, o encerramento de uma conexão pode ser melhor compreendido se interpretarmos a conexão (que é full-duplex) como um par de conexões simplex, as quais podem ser finalizadas de modo independente de sua parceira (encerramento simétrico). Quando um lado deseja encerrar a conexão, ele simplesmente envia um segmento com o flag FIN ativado e fica no aguardo de uma confirmação. Isso significa que ele não tem mais dados a enviar, embora ainda possa permanecer recebendo dados que o outro lado envia. Depois que este outro lado fizer o mesmo, a conexão estará encerrada em ambos os sentidos. Aqui, um timer também é utilizado. Ele tem o objetivo de fazer com que a resposta ao envio de um FIN seja aguardada apenas durante certo tempo. Se ela não retornar, a conexão será encerrada. Você Sabia? Não existe solução teórica para se ter certeza de que o encerramento de uma conexão TCP pode ser realizado sem perda de dados que ainda se deseja transmitir de um lado a outro? É por isso que se recorre aos timers que, na prática, funcionam muito bem. Essa questão pode ser entendida com mais detalhes por meio do chamado problema dos dois exércitos. Pesquise e descubra do que se trata esse problema e qual a sua relação com o encerramento de conexões na camada de transporte. 1.4.3 Política de transmissão do TCP Conforme comentamos quando apresentamos alguns campos presentes no cabeçalho do segmento TCP, as principais funcionalidades desse protocolo dependem, fundamentalmente, dos números de sequência, dos números de confirmação e das janelas. Tais funcionalidades estão relacionadas à política de transmissão do TCP, que contempla questões de controle de fluxo e de garantia de entrega. Uma explicação bem ilustrativa dessas questões pode ser conduzida com base na Figura 1.6. Nesta figura, observamos a troca de segmentos entre transmissor e receptor e verificamos os valores que certos campos dos cabeçalhos desses segmentos e que o buffer do receptor assumem. 15
- 16. Redes de Computadores Figura 1.6 – Política de transmissão e gerenciamento de janelas no TCP Incialmente, o buffer do receptor, que possui um tamanho de 4096 bytes, encontrase vazio. No passo (1), o transmissor envia 2048 bytes de dados, partindo de um número de sequência igual a 0 (zero). Quando este segmento é recebido, metade da janela é preenchida. Por isso, no passo (2), o receptor responde com o número de confirmação igual a 2048 e com a janela igual a 2048, identificando o tamanho do espaço vazio em seu buffer. Lembre-se que o número de confirmação tem relação com o próximo byte que o receptor espera receber; é como se, no primeiro segmento, tivessem chegado os bytes 0 a 2047 e, no próximo segmento, o primeiro byte devesse ser o byte 2048. Se, no passo (3), o transmissor enviar mais 2048 bytes, a janela do receptor será completamente preenchida, pois, nesse meio tempo, a aplicação ainda não leu nada que foi armazenado no buffer. Depois disso, em (4), o receptor responde com o número de confirmação igual a 4096 e com a janela igual a 0. Neste momento, o transmissor se encontra bloqueado, pois ele sabe que, do outro lado, não há espaço para guardar novos dados que ele venha a enviar; o transmissor poderia enviar apenas dados urgentes, com o objetivo de eliminar um processo que estivesse sendo executado no receptor, ou um segmento de 1 byte, “pedindo” para que o receptor enviasse mais uma vez o ACK e a janela atuais. Quando a aplicação, do lado do receptor, lê 2048 bytes que estavam no buffer, o estado da janela muda. Então, em (5), o receptor envia um segmento repetindo o último número de confirmação e indicando a nova situação da janela. A troca de dados volta, agora, a fluir como anteriormente. 16
- 17. Redes de Computadores Dica No link http://media.pearsoncmg.com/aw/aw_kurose_network_4/applets/flow/FlowControl. htm, encontra-se uma applet que ilustra por meio de animações um processo semelhante ao que estudamos com base na Figura 1.6. São apresentadas duas máquinas, host A e host B; o usuário pode determinar os tamanhos dos dados que essas máquinas trocam e as respectivas janelas. Quando o início da transmissão é ordenado, é possível observar as confirmações e as mudanças no buffer passando de um lado a outro da conexão. Experimente! O passo a passo descrito parece funcionar muito bem e, do ponto de vista teórico, de fato, funciona! No entanto, se alguns cuidados não forem tomados, a política de transmissão do TCP pode levar a situações de ineficiência, em que a largura de banda disponibilizada pela rede é mal aproveitada e os esforços solicitados ao transmissor e ao receptor são desnecessários. Em primeiro lugar, é importante sabermos que um transmissor não é obrigado a enviar os dados assim que os recebe do processo de aplicação. No cenário que descrevemos, antes de executar o passo (1), o transmissor poderia ter esperado o acúmulo de mais 2048 bytes para, em seguida, enviar um segmento com 4096 bytes de dados. Isso “diluiria” melhor os bytes do cabeçalho, levando a um melhor aproveitamento da rede. Consideremos, agora, uma situação em que caracteres digitados no teclado de uma máquina (transmissor) estão sendo enviados para uma máquina remota (receptor), como uma espécie de editor interativo via telnet. Você já imaginou se, a cada caractere (byte) digitado e enviado, o receptor tivesse que criar um segmento TCP apenas para enviar confirmações e atualizações de janela?! Quase a totalidade dos bytes retornados seria apenas de cabeçalho, o que, certamente, seria bastante ineficiente. Numa situação como essa, o que o receptor normalmente faz é aguardar a chegada de vários segmentos e confirmar todos de uma só vez, gerando “economia” de números de sequência e de largura de banda. Do lado do transmissor, que também estaria trabalhando de forma “burra”, pois, para cada byte enviado, haveria 40 bytes de cabeçalho (considerando os cabeçalhos das camadas de transporte e de rede), outra estratégia é adotada. O que se faz é enviar o primeiro byte recebido do processo de aplicação e acumular em buffer os bytes que vem em seguida, até que o byte pendente tenha sido confirmado. Após essa confirmação, os bytes do buffer são enviados num único segmento TCP e uma nova fase de armazenamento é iniciada até que todas as confirmações retornem. Este procedimento recursivo é conhecido como algoritmo de Nagle. Outra situação específica que pode ocorrer é a chamada síndrome da janela boba, a qual descrevemos a seguir. Imagine um processo de aplicação que repassa à camada de transporte grandes blocos de dados, que, por sua vez, são colocados num segmento TCP e enviados a uma entidade receptora. Considere ainda que, com a janela do receptor totalmente preenchida, o respectivo processo de aplicação inicia a leitura dos bytes recebidos um por vez. Quando 1 byte for lido, o receptor informará ao transmissor sua nova janela, que possui espaço para recebimento de apenas mais 1 byte. Mesmo que o transmissor já possua muitos bytes prontos para envio, ele precisará respeitar a janela do receptor e enviará apenas 1 byte de dados (além de um grande número de bytes de cabeçalho!). A janela do receptor estará novamente cheia e o transmissor deve esperar por uma nova atualização. Se, mais uma vez, a aplicação no receptor ler apenas 1 byte, esse processo voltará a se repetir de maneira indefinida (observe a Figura 1.7). 17
- 18. Redes de Computadores Figura 1.7 – Síndrome da janela boba A solução para a síndrome da janela boba foi apresentada por Clark. Em vez de o receptor informar ao transmissor pequenas mudanças em sua janela (como a mudança de apenas 1 byte, em nosso exemplo), ele espera até que um espaço maior tenha sido liberado, ou seja, até que um certo número de bytes tenha sido lido pelo processo de aplicação. Na prática, o transmissor aguarda até que o seu buffer esteja ocupado pela metade ou até que haja espaço suficiente para acomodar o tamanho máximo de segmento que as duas entidades combinaram no estabelecimento da conexão. Só depois que uma dessas condições for alcançada é que uma atualização de janela deve ser enviada; é como se o receptor dissesse ao transmissor: “pode mandar mais um bloco de bytes, pois, agora, já tenho espaço suficiente.” Obviamente, a solução de Clark e o algoritmo de Nagle são complementares. Outras ações podem ser tomadas pelas entidades de transporte a fim de melhorar a eficiência no envio dos segmentos. O próprio transmissor pode acumular um número maior de bytes, antes de enviá-los ao receptor. Apesar de estratégias como essa aumentarem o tempo de resposta, elas elevam o desempenho na transmissão, o que é importante em aplicações como a transferência de arquivos. No que diz respeito à entrega e à confirmação ordenada de dados, o receptor também pode agir. Se os segmentos 1, 2, 3, 4, 6 e 7 chegarem a um receptor, ele pode confirmar os segmentos 1, 2, 3 e 4 e manter os segmentos 6 e 7 armazenados. Quando, do lado do transmissor, o segmento 5 sofrer uma temporização, ele será reenviado. Assim que o receptor recebê-lo, ele poderá ser confirmado juntamente com os segmentos 6 e 7 (o transmissor não precisará reenviar os segmentos 6 e 7). 1.4.4 Controle de congestionamento no TCP Em seções anteriores, já conversamos um pouco sobre congestionamento e fluxo. Assim, vamos admitir que você já conhece, de forma clara, as diferenças entre essas questões e as responsabilidades que, nesse contexto, a camada de transporte precisa assumir. Nesta seção, explicaremos de forma mais detalhada a atuação do TCP na prevenção e na reação a situações de congestionamento. Veremos que o TCP recorre a algo que denominamos manipulação dinâmica das janelas e que as diversas opções fornecidas por essa estratégia permitem solucionar as questões mencionadas. Para começar, é interessante que descrevamos como a camada de transporte pode fazer pressuposições acerca do que acontece nas camadas inferiores. Nesse processo, 18
- 19. Redes de Computadores a chegada (ou não!) de confirmações desempenha um papel imprescindível. Quando uma entidade de transporte envia um segmento para um receptor, se a confirmação da entrega deste segmento não chegar, o transmissor suporá que algo “estranho” aconteceu. Antigamente, quando boa parte dos enlaces era de baixa qualidade e expunha os sinais à ação intensa das diversas fontes de distorção presentes no meio físico, era difícil saber o real motivo daquela perda. Hoje, a maioria das linhas de longa distância é de fibras ópticas, em que são raros descartes por conta de ruídos ou interferências. Assim, caso não aconteça a chegada de um segmento que uma entidade de transporte está esperando, ela atribuirá, automaticamente, este fato à ocorrência de um congestionamento em algum ponto da rede. Para colaborar com a prevenção de congestionamentos, o TCP precisa, antes de qualquer coisa, respeitar a janela do receptor (isso tem a ver com o controle do fluxo). No entanto, mesmo que o fluxo esteja sob controle, a rede pode não comportar a taxa em que transmissor e receptor desejam trocar segmentos. Por conta disso, cada transmissor deve manter duas janelas: a própria janela do receptor e a janela de congestionamento, e fazer um nivelamento por baixo, isto é, transmitir rajadas de dados segundo a menor dessas janelas. O tamanho da janela de congestionamento começa a ser definido logo após o estabelecimento de uma conexão, sendo ajustado, inicialmente, ao tamanho do segmento máximo acordado entre as duas entidades. Se um segmento de tamanho máximo for transmitido e sua confirmação retornar antes de uma temporização, a janela de congestionamento será reajustada, passando a ter o dobro do tamanho anterior. É como se a entidade de transporte pensasse: “já que a rede está suportando, vou injetar segmentos maiores...” Esse processo de sucessivos incrementos no tamanho da janela de congestionamento persiste até que um segmento enviado sofra uma temporização. Se isso acontecer, o algoritmo recuará, reatribuindo à janela de congestionamento o último valor com o qual se conseguiu uma transmissão bem sucedida. O procedimento descrito é denominado algoritmo de Jacobson ou algoritmo de inicialização lenta (perceba que não há nada de lento no algoritmo, já que ele é exponencial!). Na Internet, para que o controle de congestionamento funcione efetivamente, é necessário considerar um parâmetro adicional ao algoritmo apresentado, o limiar, que é inicialmente igual a 64KB. O algoritmo de Jacobson, para incremento da janela de congestionamento, continua funcionando normalmente. A diferença é que, quando o limiar é alcançado, o incremento da janela de congestionamento deixa de ser exponencial para se tornar linear; a cada nova confirmação recebida com sucesso, o tamanho da janela de congestionamento, em vez de dobrar, é incrementado de um número de bytes correspondente ao tamanho do segmento máximo acordado no estabelecimento da conexão. Quando uma temporização acontece, o limiar é redefinido para a metade do tamanho da janela de congestionamento em que a temporização ocorreu e o algoritmo de Jacobson volta para o começo. Essa descrição é ilustrada na Figura 1.8. É claro que qualquer alteração na janela de congestionamento deve respeitar a janela do receptor. Quando o tamanho da janela do receptor é alcançado, a janela de congestionamento para de crescer e permanece constante desde que não ocorra outra temporização e desde que a janela do receptor não mude de tamanho por algum outro motivo. 19
- 20. Redes de Computadores Figura 1.8 – Funcionamento do algoritmo de controle de congestionamento na Internet 1.4.5 Temporizadores no TCP Você já deve ter percebido que os temporizadores possuem uma importância essencial no bom funcionamento do TCP. Constantemente, temos mencionado a ocorrência de temporizações como um fator determinante para que alguma providência seja tomada na camada de transporte. O principal temporizador do TCP é o temporizador de retransmissão, que consiste no tempo em que um transmissor aguarda o retorno de uma confirmação antes de retransmitir o respectivo segmento. Bom, esse processo de esperar e decidir sobre uma retransmissão é bem simples de entender... mas você já parou para pensar sobre quanto tempo o transmissor deve ficar esperando? Definitivamente, essa não é uma questão simples. Se este tempo for superdimensionado, o transmissor pode estar esperando desnecessariamente por uma confirmação que nunca vai chegar, o que gera atraso na transmissão dos dados; por outro lado, se este tempo for subdimensionado, o transmissor pode realizar uma retransmissão desnecessária (imagine que a confirmação ainda não tinha chegado, mas já estava a caminho...), gerando um tráfego adicional e contribuindo para a sobrecarga da rede. Na camada de transporte, a obtenção do tempo “ótimo” de espera por uma confirmação requer algumas consideraçõs. Como a comunicação é fim a fim, esse tempo precisa ser, de certo modo, adaptativo; o tempo para que uma confirmação vinda de uma máquina que se encontra do outro lado do mundo retorne ao transmissor será, certamente, bem maior que aquele necessário à chegada de uma confirmação vinda de um computador que se encontra na sala ao lado (já falamos sobre isso antes). Consequentemente, os temporizadores precisarão ter um pouco mais de paciência no primeiro caso. O algoritmo que materializa esse raciocínio foi desenvolvido por Jacobson, em 1988. Para cada conexão, o TCP mantém um parâmetro denotado por RTT (round-trip time), que corresponde a melhor estimativa que, em determinado instante, se tem para o tempo de ida e volta até o destino em questão. Quando um segmento TCP é enviado, um cronômetro é acionado. Imaginando que a confirmação retorne após M unidades de tempo, o RTT é atualizado segundo a expressão 20
- 21. Redes de Computadores RTT = α.RTT + (1 – α).M, Em que α é uma constante de suavização que representa o peso dado ao antigo valor (usualmente, tem-se α = 7/8). Além disso, o algoritmo requer outra variável de suavização, D, o desvio, que é atualizado conforme a expressão D = α.D + (1 – α).|RTT – M|; O valor de α não precisa ser o mesmo utilizado na atualização de RTT. D corresponde a uma estimativa para o desvio-padrão de RTT. Finalmente, calcula-se o valor do tempo para temporização de retransmissão por Tr = RTT + 4.D. Em casos em que uma retransmissão precise ser realizada, poderia ainda acontecer de o transmissor, ao receber uma confirmação, ficar confuso. A confirmação recebida seria referente ao segmento mais antigo (que o transmissor julgara perdido) ou à sua retransmissão? Para contornar esta falha, o TCP emprega o algoritmo de Karn. Quando uma retransmissão acontece, em vez de se calcular um novo RTT e atualizar o valor de Tr, este último parâmetro é recursivamente multiplicado por dois, à espera que o segmento chegue ao seu destino pela primeira vez. No TCP, há outros temporizadores. Um deles é o temporizador de persistência. Quando a janela do receptor é completamente preenchida, conforme já vimos, ele envia ao transmissor um segmento com o campo janela igual a 0 (zero). O transmissor se colocará, então, à espera de uma atualização e, simultaneamente, ativará o temporizador de persistência. Quando for liberado um espaço na janela do receptor, isso será informado ao transmissor. Contudo, essa informação pode se perder no caminho. Diante disso, em vez de ficar esperando “eternamente”, o transmissor pode, decorrido o tempo do temporizador de persistência, perguntar ao receptor sobre alguma alteração em sua janela e reiniciar a transmissão dos dados. Outro temporizador é o de keepalive. Ele é utilizadao quando a troca de dados entre dois lados de uma conexão é cessada por um certo tempo. Decorrido o tempo definido pelo temporizador, uma das entidades pode enviar ao outro lado uma mensagem que representa algo como “você ainda está aí ou desligou sem que eu soubesse?” Se não houver resposta, a conexão é simplesmente encerrada. Há outro temporizador relacionado ao encerramento de conexões. Após a decisão de se encerrar uma conexão, esse temporizador corresponde a um tempo de espera igual a duas vezes a duração máxima dos pacotes para garantir que, quando uma conexão for fechada, todos os pacotes criados por ela serão extintos. 1.5 TCP e UDP: Tópicos Adicionais Nesta seção, abordaremos alguns tópicos adicionais envolvendo o TCP e o UDP. Iniciaremos com algumas aplicações relacionadas ao UDP, a saber, a RPC (Remote Procedure Call, chamada de procedimento remoto) e o RTP (Real-time Transport Protocol, protocolo de transporte de tempo real), e, em seguida, levantaremos alguns aspectos sobre a camada de transporte em redes sem fio e sobre questões de desempenho. 1.5.1 Chamada de procedimento remoto Em alguns tópicos estudados nesta disciplina, temos recorrido a situações em que um cliente envia uma mensagem de solicitação a um servidor, o servidor responde com uma mensagem de resposta, e o cliente bloqueia (suspende a execução) esperando essa 21
- 22. Redes de Computadores resposta. Esse é o chamado paradigma de solicitação/resposta, largamente empregado pelos programas de aplicação. Uma chamada de procedimento remoto (RPC) é um mecanismo que funciona de forma semelhante ao paradigma descrito, mas que realiza uma chamada a um procedimento (uma espécie de solicitação) sem considerar se ele é local ou remoto. O motivo de se tratar deste assunto aqui é que, embora uma RPC possa existir independentemente dos protocolos usuais da camada de transporte, ela se adapta muito bem ao UDP, o qual pode ser responsável por “levar” a solicitação do cliente ao servidor e trazer de volta a resposta. Quando se deseja implementar uma RPC, duas questões principais precisam ser levadas em consideração. Em primeiro lugar, a complexidade da rede existente entre as máquinas em que se encontram o processo chamado e o chamador é bem maior que aquela interna aos computadores (fazer uma chamada local seria bem mais fácil). Depois, as máquinas que desejam se comunicar podem ter arquiteturas e formatos de representação de dados significativamente diferentes. Em suma, para facilitar o seu funcionamento, uma RPC pode tentar fazer com que a chamada remota se pareça o máximo possível com uma chamada local. Isso é conseguido por meio de um pequeno procedimento de biblioteca chamado stub. De um lado, o programa cliente deve estar vinculado a um stub do cliente, que represente o procedimento do servidor no espaço de endereços do cliente; do lado do servidor, algo semelhante é necessário (veja a Figura 1.9). Figura 1.9 – Etapas na criação de uma chamada de procedimento remoto Primeiro, o cliente faz uma chamada ao seu stub, o que corresponde a uma chamada local. Em seguida, o stub reune os parâmetros em uma mensagem (empacotamento) e efetua uma chamda de sistema para enviar a mensagem. Depois, o núcleo (kernel) envia a mensagem da máquina cliente até a máquina servidora. Do lado do servidor, a mensagem é recebida seguindo, em ordem reversa, os passos descritos. O envio da resposta é realizada de maneira semelhante. Esta técnica pode ser empregada numa série de aplicações, como, por exemplo, no serviço desempenhado pelo DNS. Conforme estudamos, o DNS envolve basicamente o envio de parâmetros e uma resposta obtida em função dos parâmetros recebidos. 1.5.2 RTP – Protocolo de transporte de tempo real Uma área em que o UDP é amplamente utilizado é a de multimídia em tempo real. Nesse contexto, estão envolvidas aplicações como o rádio e a telefonia pela Internet, a música e o vídeo sob demanda e a realização de videoconferências. O protocolo de transporte de tempo real (RTP) surgiu como uma solução que pudesse se adequar ao 22
- 23. Redes de Computadores transporte de aplicações como essas. Na pilha de protocolos, o RTP se encontra no espaço do usuário (juntamente com a aplicação) e oferece uma espécie de biblioteca em que os diversos fluxos de multimídia podem ser armazenados (observe a Figura 1.10). Por outro lado, o RTP é genérico e independe das aplicações, o que é característico de um protocolo de transporte. É como se ele fosse um protocolo meio “híbrido”, entre a camada de transporte e a de aplicação. Figura 1.10 – (a) A posição do RTP na pilha de protocolos. (b) Encapsulamento Basicamente, o RTP serve para multiplexar diversos fluxos de dados de tempo real num único fluxo de pacotes UDP. Sobre a forma como esses dados serão transportados, não se fornece nenhuma informação adicional (a não ser em casos excepcionais). Isso significa que todas as características do UDP são preservadas, como as ausências de controle de fluxo, de erros, confirmações e retransmisssões. Conforme sugerimos em abordagens anteriores, normalmente, essa estratégia é aceitável quando se trata de multimídia. O que se faz é numerar de forma ordenada os pacotes enviados para que o receptor saiba se algum deles está faltando. Caso isso aconteça, o próprio receptor pode tomar alguma providência. No caso de um vídeo, por exemplo, é natural que cada quadro possua uma alta correlação com seus quadros adjacentes. Assim, é possível estimar quadros ausentes por meio de técnicas de interpolação. Quando isso não é possível, um quadro pode simplesmente não ser exibido. Talvez nem notássemos a ausência de um ou outro quadro dentre os 25 ou 30 que assistimos a cada segundo; pirivilegiaríamos a questão do tempo real. No cabeçalho do RTP, há um campo para que a codificação de fonte utilizada nos dados da carga útil seja especificada. Isso é essencial, pois, ao chegarem ao receptor, os dados só poderão ser exibidos corretamente se o decodificador apropriado estiver presente. O RTP também possui um campo para o timbre de hora, a fim de reduzir a flutuação (jitter) e sincronizar fluxos com origens distintas. Em conjunto com o RTP, trabalha o RTCP (Realtime Transport Control Protocol, protocolo de controle de transporte de tempo real), que se responsabiliza pelo feedback (informações sobre largura de banda, retardo, flutuação, congestionamento etc), pela sincronizaçao e pela interface com o usuário. Você Sabia? Um CODEC é um programa que permite compactar e descompactar dados digitais? Os dados em questão podem conter informações de áudio, de vídeo ou imagens. Normalmente, as técnicas utilizadas nos CODECs resultam em perda de informação, comprometendo um pouco a qualidade do que se vê ou se escuta (você percebe que a qualidade de algumas imagens salvas no formato JPG é muito pior que a qualidade de imagens em BMP?). Por outro lado, o uso de um CODEC diminui bastante o tamanho de um arquivo multimídia, facilitando o seu armazenamento e a permitindo transmissões mais rápidas. 23
- 24. Redes de Computadores 1.5.3 TCP e UDP sem fio Quando estudamos o controle de congestionamento na camada de transporte, afirmamos que uma premissa normalmente adotada é a de que os enlaces atuais para transmissão de dados são de boa qualidade, sendo implementados sobre fibras ópticas ou sendo curtos o suficiente para evitar que as fontes de distorção presentes no meio físico degradem os sinais que ali trafegam. Entretanto, se uma camada de transporte tiver que “atravessar” trechos de uma rede sem fios, a coisa muda bastante de figura. Em casos como esse, quando uma entidade TCP envia um segmento, se a confirmação não retornar em tempo hábil, haverá uma grande chance de que isso tenha acontecido por conta da falta de confiabilidade do meio não-guiado; não se terá mais tanta certeza de que este fenônemo foi provocado por um congestionamento... A estratégia básica para lidar com esse problema consiste em mudar radicalmente a maneira de agir diante de uma perda. Em redes cabeadas, quando acontece uma temporização, os transmissores diminuem o seu ritmo, à espera que a rede se recupere e retome o fôlego gradativamente. Em redes sem fio, quando uma confirmação não chega, o transmissor deve tentar reenviar o segmento o mais rápido possível. É como se o transmissor concluísse: “já que o meio físico à minha disposição é ruim e os segmentos se perdem o tempo todo, vou mandar o máximo de segmentos possível para ver se algum deles chega!” O fato é que a maioria das redes é heterogênea, isto é, parte é implementada sobre meios guiados (normalmente o backbone) e outra parte pode ser implementada sem fios (normalmente, a “última milha”). Uma solução para isso é dividir o caminho a ser percorrido em duas partes. Essa técnica é denominada TCP indireto e é apresentada na Figura 1.11. Figura 1.11 – Divisão da conexão TCP em duas conexões Na primeira parte, é estabelecida a conexão TCP #1, que funciona como um TCP sobre redes cabeadas. É como se seu destino final fosse a estação-base. No segundo trecho, sem fios, estabelece-se a conexão TCP #2, que adota a estratégia descrita para a injeção de segmentos na rede. A dificuldade é que, quando o transmissor receber as confirmações de entrega, elas significarão que os segmentos chegaram à estaçao-base e não à estação móvel, a qual representa, de fato, o destino final dos dados. Isso pode gerar confusão. Além do mais, a divisão do que deveria ser uma só conexão em duas partes viola a semântica do TCP. Uma solução para isso consiste em permanecer com apenas uma conexão de transporte e realizar modificações no código da camada de rede da estação-base. Resumidamente, o que se faz é instalar uma espécie de espião na estação-base, capaz de monitorar o que é enviado e recebido pelo enlace sem fio. Os segmentos enviados para a estação móvel ficam guardados na estação-base e quando o espião percebe que um deles não foi confirmado, ele mesmo se encarrega de reenviar, sem comunicar nada ao transmissor. A desvantagem é que o transmissor pode sofrer uma temporização, se muitas tentativas tiverem que ser feitas para entregar um segmento à estação móvel. 24
- 25. Redes de Computadores No caso do UDP, um ambiente sem fios também pode trazer alguns problemas. Por mais que as aplicações saibam que o UDP não é confiável, elas esperam que ele ofereça o mínimo de desempenho neste sentido. Quando acontece uma mudança repentina no cenário da rede, o efeito sobre essas aplicações pode ser bastante danoso. É como se deixássemos de perder um ou outro quadro de um vídeo e passássemos a perder uma série de quadros em sequência e, mesmo que pudéssemos esperar por uma retransmissão, não tivéssemos como solicitá-la. Com o ganho de popularidade das redes sem fio, novas estratégias têm sido desenvolvidas para lidar com situações como essa. Aprenda Praticando Agora é chegada a hora de você praticar os conceitos aprendidos. Para isso, alguns exercícios foram selecionados para você avaliar seu entendimento do nosso primeiro capítulo. Você deverá procurar entender os exercícios resolvidos e suas respectivas respostas com o intuito de consolidar os conceitos aprendidos neste capítulo. Algumas questões dos exercícios propostos fazem parte das atividades somativas que você deverá responder em relação ao capítulo 1, do Volume 2, de acordo com as orientações e prazos sugeridos pelo seu professor e tutor. Lista de exercícios propostos 1. O que você mencionaria como principais funcionalidades da camada de transporte? 2. O handshake de três vias é um procedimento básico no estabelecimento de uma conexão na camada de transporte. Caso não efetuássemos o último passo desse procedimento, faria alguma diferença? A conexão seria estabelecida normalmente em qualquer situação ou algum impasse poderia ser gerado? 3. Suponha que um processo no computador C possua um socket UDP com númer de porta 6790 e que o computador A e o computador B, individualmente, enviem um segmento UDP ao computador C com número de porta de destino 6790. Esses dois segmentos serão encaminhados para o mesmo socket no computador C? Se sim, como o processo no computador C saberá que esses dois segmentos vieram de duas máquinas diferentes? 4. Por que o UDP existe? Não seria suficiente deixar que os processos dos usuários enviassem pacotes IP brutos? 5. Por que o tráfego de voz e de vídeo é frequentemente enviado por meio do UDP e não do TCP na Internet de hoje? 6. Numa conexão TCP, um transmissor que recebe o anúncio de uma janela igual a 0 (zero) sonda o receptor periodicamente para descobrir quando a janela se torna diferente de 0. Por que o receptor precisaria de um temporizador extra se ele fosse responsável por informar que sua janela anunciada se tornou maior que 0 (ou seja, se o transmissor não sondasse)? 7. Apresente uma desvantagem potencial do uso do algoritmo de Nagle numa rede muito congestionada. 8. Descreva um cenário em que pode acontecer a chamada síndrome da janela boba. 9. Suponha que um host queira medir a confiabilidade de um enlace enviando pacotes e medindo a porcentagem dos que são recebidos (os roteadores, por exemplo, fazem isso); Explique a possibilidade de se fazer isso por uma conexão TCP. 25
- 26. Redes de Computadores 10. Suponha que a janela de congestionamento do TCP seja definida como 36 KB e que ocorra uma temporização. Qual será o tamanho da janela se as próximas quatro rajadas de transmissão forem bem sucedidas? Suponha que o tamanho máximo do segmento seja 2 KB. 11. Os hosts A e B estão se comunicando por meio de uma conexao TCP, e o host B já recebeu de A todos os bytes até o byte 126. Suponha que o host A envie, então, dois segmentos para o host B sucessivamente. O primeiro e o segundo segmentos contêm 70 e 50 bytes de dados, respectivamente. No primeiro segmento, o número de sequência é 127, o número de porta de origem é 302, e o número de porta de destino é 80. O host B envia uma confirmação ao receber um segmento do host A. a. No segundo segmento enviado do host A para B, quais são o número de sequência, a porta de origem e a porta de destino? b. Se o primeiro segmento chegar antes do segundo, na confirmação do primeiro segmento que chegar, qual é o número de confirmação, da porta de origem e da porta de destino? c. Se o segundo segmento chegar antes do primeiro, na confirmação do primeiro segmento que chegar, qual é o número de confirmação? d. Suponha que dois segmentos enviados por A cheguem em ordem a B. A primeira confirmação é perdida e a segunda chega após o primeiro intervalo de temporização. Elabore um diagrama de temporização mostrando esses segmentos, e todos os outros, e as confirmações enviadas (assuma que não há outras perdas de pacotes). Para cada segmento de seu desenho, apresente o número de sequência e o número de bytes de dados; para cada confirmação adicionada por você, apresente o número de confirmação. 12. Se o tempo de viagem de ida e volta no TCP, denominado RTT, for igual a 20 ms, e se as confirmações seguintes chegarem depois de 26, 32 e 24 ms, respectivamente, qual será a nova estimativa para RTT empregando-se o algoritmo de Jacobson? Considere α = 0,9. 13. Por que o UDP se adequa tão bem ao transporte de uma RCP (chamda de procedimento remoto)? 14. Se perguntássemos em que camada da pilha de protocolos se encontra o RTP (protocolo de transporte de tempo real), o que você responderia? 15. Explique o motivo pelo qual se diz que o TCP indireto, utilizado em redes sem fio, viola a semântica do TCP. Conheça Mais Caro(a) aluno(a), ao longo do nosso estudo, você deve ter percebido que os protocolos da camada de transporte são de essencial importância para o bom funcionamento de uma rede de computadores. Eles estão presentes em diversos cenários e, idealmente, precisam se comportar bem, independentemente da estrutura de rede sobre a qual são implementados. Hoje, o interesse pelas redes sem fio é bastante grande, por conta da mobilidade e da facilidade de instalação que elas provêem. Nesse contexto, encontra-se uma tecnologia denominada WiMAX, que é, basicamente, uma rede sem fio metropolitana e de banda larga. Nos links a seguir, você vai encontrar o vídeo de uma apresentação intitulada 26
- 27. Redes de Computadores Análise de Desempenho do TCP sobre Redes WiMAX, realizada em 2008, na 25ª reunião do Grupo de Trabalho de Engenharia e Operação de Redes, GTER (http://gter.nic.br). Está disponível, também, a apresentação em .pdf utilizada na palestra. Apesar de a apresentação discutir alguns pontos que, talvez, você ainda não conheça, procure identificar, ao longo do vídeo, pontos que você estudou so longo deste capítulo e perceba a aplicabilidade prática de cada conceito aprendido. Vídeo: ftp://ftp.registro.br/pub/gter/gter25/videos/mp4/gter-07-desempenho-tcp-wimax. mp4 Arquivo em .pdf: ftp://ftp.registro.br/pub/gter/gter25/07-desempenho-tcp-wimax.pdf Atividades e Orientações de Estudos Dedique, pelo menos, 10 horas de estudo para o Capítulo 1. Você deve organizar uma metodologia de estudo que envolva a leitura dos conceitos apresentados e pesquisas sobre o tema, usando a Internet e livros de referência. Vamos trocar idéias nos fóruns temáticos desta disciplina no ambiente virtual, pois a interação com colegas, tutores e o professor da disciplina irá ajudá-lo a refletir sobre aspectos fundamentais tratados aqui. Os chats também serão muito importantes para a interação em tempo real com o seu tutor virtual, seu professor e seus colegas. Também é importante que você leia atentamente o guia de estudo da disciplina, pois nele você encontrará a divisão de conteúdo semanal, ajudando-o a dividir e administrar o seu tempo de estudo semanal. Procure responder as atividades propostas como atividades somativas para este capítulo, dentro dos prazos estabelecidos pelo seu professor, pois você não será avaliado apenas pelas atividades presenciais, mas também pelas virtuais. Muitos alunos não acessam o ambiente e isso poderá comprometer a nota final. Não deixe que isso aconteça com você! Os assuntos abordados neste capítulo podem ser encontrados no Quiz de número 1 da disciplina de Redes de Computadores. Através do Quiz você poderá avaliar o seu próprio desempenho. Após respondê-lo, você terá o resultado de seu desempenho e conhecerá as suas deficiências, podendo supri-las nas suas próximas horas de estudo. Vamos Revisar? Neste capítulo, você estudou definições e conceitos relacionados à camada de transporte. Dentro da abordagem que temos desenvolvido, percebemos que a camada de transporte é essencial para que cada processo de aplicação envie e receba dados da maneira adequada. Já pensou se um e-mail enviado por você aparecesse na tela do computador de destino quando o usuário estivesse solicitando uma página da Internet!? A grosso modo, é esse “confusão” entre as aplicações que a camada de transporte ajuda a evitar. Aprendemos que os principais protocolos da camada de transporte na Internet são o TCP e o UDP. O primeiro tem como responsabilidade principal cobrir certas “brechas” deixadas pela rede. Quando enviamos dados a outro computador, queremos ter a certeza de que eles chegaram no destino, de que a máquina remota os aceitou e de que eles foram 27
- 28. Redes de Computadores entregues em ordem ao respectivo processo de aplicação. São coisas desse tipo que o TCP garante, por meio de mecanismos baseados em números de sequência e confirmação e utilizando controle de fluxo e de congestionamento. O UDP, por sua vez, encontra aplicabilidade em cenários em que uma perda, talvez, não faça tanta diferença. Nesse contexto, enquadram-se os serviços multimídia e aqueles baseados em solicitação/resposta. No caso de voz ou vídeo pela Internet, dependendo do CODEC utilizado, quadros ou pacotes perdidos podem ser estimados via interpolação; no caso de um pedido a um servidor, se uma resposta não acontece, o pedido pode ser simplesmente enviado outra vez. TCP e UDP, cada um com sua importância, continuam fazendo parte da “coração” das redes de computadores, adaptando-se aos novos cenários e trabalhando em conjunto com as tecnologias emergentes. No próximo capítulo, estudaremos a camada de rede e comprenderemos melhor sua relação com o que já aprendemos até agora. 28
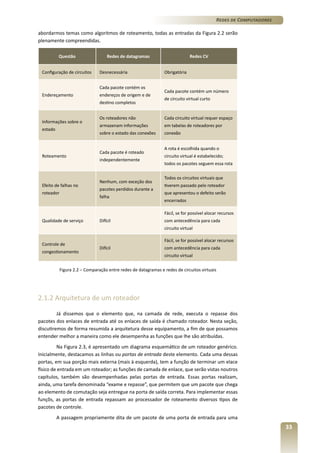
- 29. Redes de Computadores Capítulo 2 – A Camada de Rede e o Protocolo IP Vamos conversar sobre o assunto? Caro(a) aluno(a), Durante a nossa abordagem sobre a camada de transporte, muitas vezes, fizemos questão de enfatizar que “os protocolos da camada de transporte devem funcionar bem, independentemente do que aconteça na rede”. Mas o que, de fato, pode estar acontecendo na rede? Que rede é essa e quais são as suas atribuições? É isso que começaremos a esclarecer neste capítulo, quando realizaremos nosso estudo sobre a camada de rede, localizada imediatamente abaixo da camada de transporte. Diferentemente da camada de transporte, a camada de rede não é uma camada fim a fim; suas partes, além de serem implementadas nos sistemas finais (hosts), aparecem também nos roteadores, os “caras” que dizem o caminho que os dados devem seguir para chegar ao destino. Você já deve estar imaginando a trabalheira que essa camada deve ter... para que tudo dê certo, ela vai precisar recorrer a esquemas de endereçamento diferentes daquele usado na camada de transporte. Antes, o objetivo era entregar os dados (já recebidos por um host) aos processos de aplicação corretos (pra isso, usamos a ideia de portas, lembram?); agora, queremos levar os dados de um computador a outro que pode estar do outro lado do mundo! Na camada de rede, falaremos bastante sobre roteamento e discutiremos os algoritmos responsáveis por essa tarefa. Veremos que, para que tudo funcione bem, a rede deve estar organizada de uma forma hierárquica e que, em níveis diferentes, algoritmos diferentes devem ser empregados. De uma maneira mais específica, estudaremos aspectos relacionados à camada de rede na Internet. Falaremos sobre o famoso protocolo IP (Internet Protocol), a tradução de endereço de rede (NAT, Network Address Translation), a fragmentação de datagramas e o protocolo de mensagem de controle da Internet (ICMP, Internet Control Message Protocol). Além disso, abordaremos os principais aspectos do IPv6. Antes de tudo isso, porém, inciemos com uma seção introdutória em que aprenderemos conceitos básicos, como os que permitem diferenciarmos redes baseadas em datagramas daquelas baseadas em circuitos virtuiais e conhecermos a arquitetura básica de um roteador bem como suas principais funções. 2.1 Introdução Nesta seção, discutiremos alguns conceitos importantes para darmos sequência ao nosso estudo. Em primeiro lugar, precisamos entender qual é, basicamente, a função da camada de rede no que diz respeito à sua interação com as demais camadas. Já sabemos que, num host, os processos de aplicação entregam os dados a serem enviados à camada de transporte que, por sua vez, os coloca em segmentos de protocolos como o TCP e o UDP. Os segmentos de transporte são, então, entregues às camadas inferiores e adentram no enlace por meio do qual serão transmitidos. 29
- 30. Redes de Computadores Quando alcançam um roteador, os dados precisam saber para onde vão; um roteador possui várias linhas de entrada e várias linhas de saída. O roteador, então, retira os dados do enlace pelo qual os recebeu e utiliza um algoritmo de roteamento, para determinar para que linha de saída os dados devem ser repassados. O repasse propriamente dito dos dados é realizado conforme tabelas que são mantidas pelos roteadores. Para realizar essa tarefa, o roteador precisa implementar até a camada de rede (veremos que é no cabeçalho do protocolo utilizado na camada de rede que se encontra o endereço final dos dados); por motivos óbvios, ele não precisa implementar a camada de transporte e menos ainda a de aplicação. Esse procedimento é ilustrado na Figura 2.1. Figura 2.1 – A camada de rede Podemos falar um pouco mais sobre as tabelas de repasse... Como dissemos, no cabeçalho do protocolo da camada de rede, encontra-se um endereço ou alguma outra informação sobre o destino que os dados precisam alcançar. A tabela consiste, basicamente, em duas colunas, relacionando destinos a serem alcançados com linhas de saída do roteador. Recebido um datagrama, basta que se verifique seu destino e se procure na tabela a linha de saída que deve ser usada. A montagem das tabelas é feita com base nos algoritmos de roteamento, que podem ser centralizados, descentralizados, estáticos, dinâmicos. Como regra geral, um algoritmo de roteamento tentará, respeitando certas restrições, fazer com que um datagrama percorra o caminho com menor custo possível (veremos que o que se entende por custo pode envolver muita variáveis...). Em alguns casos, a determinação desse caminho pode envolver o estabelecimento de conexões. Isso mesmo! Como na camada de transporte... no entanto, no presente contexto, isso tem uma finalidades bem específicas como a reserva de recursos e o estabelecimento de prioridades. Outro conceito a ser discutido nesta introdução é o que chamamos de modelo de serviço de rede, que define tipos de serviços que a camada de rede poderia oferecer para o transporte dos dados (isso não significa que a camada de transporte pode “relaxar” e confiar plenamente na camada de rede). Entre esses serviços se encontram: » Entrega garantida: assegura que o pacote (independentemente do atraso que venha sofrer); chegará ao seu destino » Entrega garantida com atraso limitado: incrementa o serviço descrito acima, estabelecendo limites de atraso. Entre os serviços que se prestam a um fluxo de pacotes entre uma fonte e um destino determinados, podemos destacar a (i) entrega de pacotes na ordem, (ii) a garantia de uma largura de banda mínima, (iii) a garantia de um jitter máximo (jitter corresponde a uma medida de variabilidade dos atrasos sofridos pelos pacotes) e (iv) os serviços de segurança. Na prática, diversas variações dos exemplos citados são possíveis. Quando se trata de Internet, entretanto, o modelo de serviço oferecido se resume ao de melhor esforço. Com ele, não há garantias de entrega em ordem e nem mesmo garantias de entrega (mesmo que fora de ordem). Mais tarde, veremos que isso não significa que a camada de rede não desempenhe bem as suas responsabilidades. Noutras arquiteturas de rede, há serviços que vão além do serviço de melhor 30
- 31. Redes de Computadores esforço oferecido pela Internet. Um bom exemplo disso acontece nas redes ATM, que oferece as chamadas classes de serviço. Entre essas classes, encontra-se a de taxa constante de bits, que é voltada à transmissão de pacotes que “carregam” voz, por exemplo. É como se a rede tentasse imitar uma comutação por circuitos, que é usada no sistema telefônico convencional; outra classe é a de taxa variável de bits, que se aplica, por exemplo, à transmissão de vídeo (diferentes quadros de um mesmo vídeo podem ser compactados a taxas diferentes); tem-se, ainda, o serviço de rede de taxa de bits disponível, que pode ser caracterizado como um serviço de melhor esforço ligeiramente incrementado. 2.1.1 Redes de circuitos virtuais e de datagramas Durante os nossos estudos do capítulo 1, vimos que a camada de transporte é capaz de oferecer serviços orientados a conexão e serviços não orientados a conexão. A camada de rede também contempla ambas as possibilidades, introduzindo, naturalmente, algumas mudanças na maneira em que esses serviços são oferecidos. Já dissemos que a implementação de um serviço orientado a conexão, na camada de transporte, ocorre na borda da rede; na camada de rede, essa responsabilidade é fundamentalmente dos roteadores. Além disso, a comunicação na camada de rede é entre hosts apenas, não havendo qualquer relação com os processos de aplicação, como ocorre na camada de transporte. Quando quisermos nos referir a redes que oferecem um serviço orientado a conexão, utilizaremos a terminologia redes de circuitos virtuais (redes CV); quando nos referirmos a redes que oferecem um serviço não orientado a conexão, empregaremos o termo redes de datagramas. Muitas arquiteturas de redes alternativas, como ATM e Frame Relay, se baseiam em circuitos virtuais. Um circuito virtual consiste, basicamente, num caminho entre hosts de origem e de destino; uma espécie de sequência de saltos desde o host de origem, passando por diversos roteadores, até alcançar o host de destino. Um pacote que precise ser encaminhado ao longo de uma rede dessas deve ser marcado com um número de circuito virtual, para que, com o auxílio de tabelas de repasse, os roteadores possam encaminhá-lo. O principal objetivo dessa estratégia é evitar a necessidade de escolher uma nova rota para cada pacote enviado. No momento em que uma conexão é estabelecida, escolhe-se uma rota desde o host de origem até o de destino, a qual é armazenada e utilizada por todo o tráfego que flui pela conexão. Numa rede de datagramas, sempre que um sistema final quer enviar um pacote, ele “escreve” no pacote o endereço do destino que se deseja alcançar e o envia para dentro da rede. Isso é o que faz, por exemplo, a Intenet! Como nenhum circuito virtual é estabelecido, os roteadores não têm necessidade de manter certas informações, a fim de garantir o uso do mesmo percurso por pacotes que virão mais tarde. Quando um pacote chega ao roteador, este usa o endereço de destino do pacote para “informar” que linha de saída ele deve utilizar (aqui, recorre-se às tabelas de repasse, introduzidas no início deste capítulo). Pode ser que, noutro momento, a linha de saída escolhida anteriormente já não seja a mais indicada para pacotes com o mesmo destino. É importante esclarecermos que as tabelas de repasse de um roteador não precisam ter uma entrada para cada endereço existente no mundo. Isso tornaria as tabelas muito grandes e difíceis de serem armazenadas na memória de um roteador. Na verdade, o que se escreve nas tabelas é algo como “se o endereço de destino do pacote estiver na faixa de X a Y, então, envie-o pela linha de saída Z.” Assim, os roteadores precisam examinar apenas os prefixos dos endereços de destino dos pacotes recebidos. Para ilustrar melhor essa possibilidade, considere o seguinte exemplo numérico, que poderia representar as informações a serem escritas numa tabela de repasse. 31
- 32. Redes de Computadores Faixa de endereços de destino Linha de saída 11001000 00010111 00010000 00000000 até 0 11001000 00010111 00010111 11111111 11001000 00010111 00011000 00000000 até 1 11001000 00010111 00011000 11111111 11001000 00010111 00011001 00000000 até 2 11001000 00010111 00011111 11111111 caso contrário 3 Observando os prefixos, percebe-se que as decisões dos roteadores poderiam ser tomadas com base apenas nos quatro registros seguintes: Prefixo do endereço Linha de saída 11001000 00010111 00010 0 11001000 00010111 00011000 1 11001000 00010111 00011 2 caso contrário 3 No final das contas, é como se apenas parte do endereço de destino escrito num pacote precisasse ser utilizado para que um roteador desempenhasse sua tarefa; quanto mais perto do destino final de um pacote um roteador se encontrar, mais detalhes do endereço ele vai “ler”, a fim de que o pacote seja encaminhado de maneira cada vez mais específica. Essa condição caracteriza o que chamamos de roteamento hierárquico. Uma boa analogia para esse processo é o que ocorre na entrega de uma correspondência pelo correio usual. Quando um grande centro de distribuição recebe uma encomenda, talvez, ele só se interesse em saber para que cidade aquele pacote está endereçado (é como se a cidade representasse o prefixo que abordamos no exemplo); não há porque este grande centro se preocupar, por exemplo, com o número da casa em que o destinário reside. Quando a encomenda é repassada a um centro de distribuição municipal, será importante saber em que bairro o destinatário se encontra; isso se consegue utilizando o CEP. Quando o carteiro tem a encomenda em mãos e acha a rua em que precisa deixá-la, aí sim ele precisará observar o detalhe final, isto é, o número da casa do destinatário, para, finalmente, realizar a entrega. Para encerrarmos este tópico, apresentamos uma tabela comparando alguns aspectos das redes CV e das redes de datagramas. Quando, mais adiante neste capítulo, 32
- 33. Redes de Computadores abordarmos temas como algoritmos de roteamento, todas as entradas da Figura 2.2 serão plenamente compreendidas. Questão Configuração de circuitos Redes de datagramas Desnecessária Cada pacote contém os Endereçamento endereços de origem e de destino completos Redes CV Obrigatória Cada pacote contém um número de circuito virtual curto estado Roteamento Efeito de falhas no roteador Os roteadores não Cada circuito virtual requer espaço armazenam informações em tabelas de roteadores por sobre o estado das conexões Informações sobre o conexão Cada pacote é roteado independentemente Nenhum, com exceção dos pacotes perdidos durante a falha A rota é escolhida quando o circuito virtual é estabelecido; todos os pacotes seguem essa rota Todos os circuitos virtuais que tiverem passado pelo roteador que apresentou o defeito serão encerrados Fácil, se for possível alocar recursos Qualidade de serviço Difícil com antecedência para cada circuito virtual Controle de congestionamento Fácil, se for possível alocar recursos Difícil com antecedência para cada circuito virtual Figura 2.2 – Comparação entre redes de datagramas e redes de circuitos virtuais 2.1.2 Arquitetura de um roteador Já dissemos que o elemento que, na camada de rede, executa o repasse dos pacotes dos enlaces de entrada até os enlaces de saída é chamado roteador. Nesta seção, discutiremos de forma resumida a arquitetura desse equipamento, a fim de que possamos entender melhor a maneira como ele desempenha as funções que lhe são atribuídas. Na Figura 2.3, é apresentado um diagrama esquemático de um roteador genérico. Inicialmente, destacamos as linhas ou portas de entrada deste elemento. Cada uma dessas portas, em sua porção mais externa (mais à esquerda), tem a função de terminar um elace físico de entrada em um roteador; as funções de camada de enlace, que serão vistas noutros capítulos, também são desempenhadas pelas portas de entrada. Essas portas realizam, ainda, uma tarefa denominada “exame e repasse”, que permitem que um pacote que chega ao elemento de comutação seja entregue na porta de saída correta. Para implementar essas funçõs, as portas de entrada repassam ao processador de roteamento diversos tipos de pacotes de controle. A passagem propriamente dita de um pacote de uma porta de entrada para uma 33
- 34. Redes de Computadores porta de saída (comutação) é realizada pelo elemento de comutação. Dentre as várias maneiras de realizar uma comutação, destacamos as seguintes: » Comutação por memória: empregada nos primeiros e mais simples roteadores, funcionava como um computador convencional, em que a comutação entre entrada e saída era controlada pela CPU (que representava o processador de roteamento). As portas de entrada e saída eram como os dispositivos de entrada e saída usuais. » Comutação por barramento: as portas de entrada transferem um pacote diretamente para as portas de saída por um barramento compartilhado, sem a necessidade de um processador. Lembramos que um barramento é uma espécie de estrutura matricial, que permite que qualquer linha de entrada (linha da matriz) se ligue, em algum momento, a qualquer linha de saída (coluna da matriz). Como o barramento é compartilhado, somente um pacote pode ser transferido por vez. » Comutação por uma rede de interconexão: corresponde a uma rede de interconexão mais complexa (do tipo crossbar, por exemplo), com o objetivo de superar as restrições ocasionadas pelo uso de um barramento compartilhado. O processador de roteamento roda os algoritmos de roteamento, mantém as tabelas de repasse e executa funções de gerenciamento de rede internas ao roteador. As portas de saída desempenham o papel reverso ao das portas de entrada, isto é, recebem os pacotes do elemento de comutação, que haviam sido armazenados numa memória, e os transmitem pelo enlace de saída. Figura 2.3 – Arquitetura de um roteador genérico Uma questão que está diretamente ligada ao roteador e que é bastante crítica para o funcionamento adequado da camada de rede é o enfileiramento. Esse fenômeno pode ocorrer de diversas formas e sua principal consequência, a perda de pacotes, pode acontecer em vários pontos do roteador. Consideremos, por exemplo, uma situação em que os pacotes chegam às portas de entrada a determinada taxa e que o elemento de comutação tem velocidade suficiente para manipulá-los para as portas de saída. Se, sequencialmente, diversos pacotes tiverem que ser transferidos para uma mesma porta de saída, por “ordem” do algoritmo de roteamento, uma fila irá se formar e a memória deste elemento poderá não ter espaço suficiente para armazená-los. Isso ocasionaria o descarte de pacotes. Nesse contexto, torna-se importante o que chamamos de política de enfileiramento, que corresponde à tarefa, desempenhada por um escalonador de pacotes colocado na porta de saída, de determinar os pacotes que serão preservados em situações de descarte. Tal escalonamento tem relação com o que chamamos de qualidade de serviço (estudaremos este tema mais à frente). Filas e descartes também podem ocorrer nas portas de entrada, caso os pacotes cheguem a uma taxa tão alta a ponto de a memória ser preenchida antes da entrega, via comutação, às portas de saída. 34
- 35. Redes de Computadores 2.2 Algoritmos de roteamento Agora que conhecemos os conceitos gerais acerca da camada de rede, iniciaremos nosso estudo sobre os algoritmos de roteamento. Perceba que ainda não estamos nos concentrando no que é usado ou no que acontece na Internet especificamente. Falaremos, inicialmente, dos algoritmos de maneira geral e, oportunamente, mencionaremos redes práticas que os empregam. Ao longo do nosso estudo, veremos que há algumas propriedades que devem ser privilegiadas por qualquer algoritmo de roteamento. Naturalmente, um algoritmo de roteamento deve ser correto e o mais simples possível. Além do mais, deve ser robusto o suficiente para continuar funcionando por muito tempo, diante de falhas e mudanças que podem acontecer na rede. Um algoritmo de roteamento deve ser estável, fornecendo com clareza seus resultados e evitando situações instáveis que levem a loops ou a sobrecargas; deve ser prezar, simultaneamente, pela equidade (distribuição dos recursos da rede de forma justa) e pela otimização (oferecer as melhores alternativas possíveis para o encaminhamento de um pacote). Comumente, os algoritmos de roteamento são divididos em não-adaptativos (estáticos) e adaptativos. Os primeiros tomam suas decisões off-line, isto é, sem levar em conta mudanças que podem ocorrer, ao longo do tempo, no tráfego e na topologia da rede. Os algoritmos adaptativos podem ter suas decisões modificadas, conforme a condição atual da rede. Para isso, é necessário que, de tempos em tempos, o algoritmo seja executado e que as novas informações sejam, de alguma maneira, propagadas por toda a rede. 2.2.1 O princípio de otimização O propósito de todos os algoritmos de roteamento é encontrar a melhor rota entre dois nós de uma rede. Uma descrição geral do que isso significa pode ser realizada por meio do chamado princípio da otimização. Considere a Figura 2.4 (a), na qual é apresentada uma subrede, com nós (roteadores) identificados pelas letras de A a O, e considere, particularmente, os nós B, L e K. O princípio da otimização afirma que, se o roteador K se encontra na rota ótima rLB entre os nós L e B, então, o caminho ótimo rKB entre os nós K e B estará na mesma rota. Quando estendemos esta ideia aos demais nós da rede, considerando seus melhores caminhos atá o nó B, obtemos a Figura 2.4 (b), que representa uma árvore de escoamento. Toda a “luta” de um algoritmo é para encontrar as árvores de escoamento de cada um dos nós de uma rede, pois, assim, será conhecido o melhor caminho entre cada par de nós. Nas seções seguintes, abordaremos as estratégias utilizadas para alcançar este objetivo. Figura 2.4 – (a) Uma subrede. (b) Uma árvore de escoamento para o roteador B 35
- 36. Redes de Computadores 2.2.2 Roteamento pelo caminho mais curto Uma técnica bem conhecida no contexto dos algoritmos de roteamento e empregada de diversas formas é a de roteamento pelo caminho mais curto. Para aplicar essa estratégia, os roteadores de uma rede são enxergados como nós de um grafo e os enlaces que os interligam são tratados como arcos (como na Figura 2.4). A rota entre um par de roteadores consistirá, então, no caminho mais curto entre eles no grafo. A ideia de caminho mais curto pode, entretanto, ser entendida de diversas maneiras. Num grafo como o que descrevemos, se colocarmos sobre os arcos números correspondentes ao peso de cada um deles, esses pesos podem significar uma distância geográfica, um retardo médio de enfileiramento, uma largura de banda etc. Um caminho mais curto geograficamente pode não ser o caminho mais curto do ponto de vista de retardo, por exemplo... De qualquer forma, o que desejamos é encontrar um caminho em que a soma dos pesos aos quais nos referimos seja mínima. O algoritmo mais utilizado para isso é o de Dijkstra. O funcionamento do algoritmo de Dijkstra pode ser explicado com base na Figura 2.5, em que desejamos encontrar o caminho mais curto entre os nós A e D. Na parte (a) da figura, são identificados os nós e os pesos de cada arco. Em cada passo, o que se faz é rotular os nós vizinhos do nó ativo (na figura, indicados pelas setas) com a “distância” percorrida desde o nó inicial (A) e com o nó anterior ao longo do caminho sendo definido. Na parte (c) da figura, por exemplo, o nó E é identificado com 4 (peso do percurso ABE) e com B (nó anterior a E). Os rótulos de cada nó podem ser atualizados. Os passos são repetidos até que se chegue ao nó de destino. O caminho mais curto é determinado observando, a partir do nó de destino, os rótulos que informam o nó antecessor até que se chegue ao nó de origem. Lembramos que este é um algoritmo não-adaptativo. Figura 2.5 – As cinco primeiras etapas utilizadas no cálculo do caminho mais curto entre os nós A e D pelo algoritmo de Dijkstra. As setas indicam o nó ativo 36
- 37. Redes de Computadores Dica No link http://www.netbook.cs.purdue.edu/animations/shortest%20path.html, encontra-se uma animação em flash que ilustra a definição do caminho mais curto entre dois nós de uma rede por meio do algoritmo de Dijkstra. Acesse este link e compare o seu conteúdo com a explicação que apresentamos nesta seção. 2.2.3 Inundação Outro algoritmo de roteamento não-adaptativo é o algoritmo de inundação (flooding). Esta técnica consiste em enviar cada pacote de entrada para todas as portas de saída do roteador, exceto para aquela pela qual o pacote foi recebido. É claro que este algoritmo, utilizado sem qualquer cuidado, faz com que um número imenso de pacotes seja criado; um mesmo pacote passaria diversas vezes por um mesmo roteador e pacotes poderiam viajando pela rede por um tempo indefinido. Para evitar esse tipo de coisa, algumas medidas são normalmente adotadas. Uma delas consiste em inserir um contador de saltos no cabeçalho dos pacotes. A cada salto, esse contador seria decrementado e, quando se atingisse o valor 0 (zero), o pacote seria eliminado. Outra abordagem consiste em marcar um pacote com identificadores dos nós pelos quais ele já passou. Assim, quando um roteador recebesse um pacote, ele saberia se é um pacote novo antigo e poderia decidir entre descartá-lo ou repassá-lo a diante. O algoritmo poderia trabalhar, ainda, de forma seletiva, fazendo com que os roteadores só enviassem os pacotes às portas de saída que estão, com maior probabilidade, numa das direções do destino em que a entrega deve ser feita. Podemos mencionar quatro situações em que o algoritmo de inundação é útil. A primeira delas é em aplicações militares. Num ambiente de guerra, vários roteadores podem ser destruídos ao mesmo tempo. Utilizar um algoritmo de roteamento que direcionasse os pacotes para roteadores específicos (que poderiam estar “fora do ar”) seria muito ineficiente. Um segundo cenário consiste numa rede em que bancos de dados distribuídos tivessem que ser atualizados simultaneamente. A terceira situação corresponde a um ambiente de redes sem fio em que os dados enviados por uma estação tivessem que ser recebidos por todas as estações dentro de um certo raio de alcance do rádio. Finalmente, como o algoritmo de inundação sempre utiliza a melhor rota (dentre as várias rotas que são paralelamente escolhidas), ele pode servir como referência na avaliação do desempenho de outros algoritmos de roteamento. 2.2.4 Roteamento com vetor de distância Nas redes de computadores modernas, o roteamento funciona melhor quando é possível levar em conta as mudanças ocorridas ao longo do tempo, isto é, quando se emprega um algoritmo adaptativo. Nesta seção, estudaremos o primeiro algoritmo de roteamento adaptativo importante, o de roteamento com vetor de distância, que foi utilizado na ARPANET e na Internet (RIP, Routing Information Protocol). No roteamento com vetor de distância, parte-se do princípio de que cada roteador conhece a “distância” até cada um dos seus vizinhos (o peso dos arcos pelos quais ele se liga a seus vizinhos). O roteador obtém as distâncias até os outros nós (não vizinhos) por meio de informações que são passadas pelos seus vizinhos. O resultado disso é uma tabela que 37
- 38. Redes de Computadores fornece a melhor distância conhecida até cada destino e determina a porta de saída que deve ser utilizada para se chegar lá. Define-se um intervalo de tempo regular, após o qual as tabelas dos roteadores são atualizadas (novas distâncias entre um roteador e seus vizinhos podem ser obtidas e as melhores rotas podem ser modificadas). A grande brecha deste algoritmo consiste num problema conhecido como contagem até infinito, que surge do fato de cada roteador não ter uma visão global da rede. Noutras palavras, quando um roteador A informa a um roteador B que possui uma boa rota entre B e um terceiro roteador, B não tem como saber se ele mesmo está no caminho. Numa situação em que algum roteador da rede tenha falhado, isso pode levar a uma situação de instabilidade e o algoritmo pode não convergir. Sugerimos que você procure mais detalhes sobre a contagem até infinito em fontes complementares de pesquisa, como a Internet e as referências bibliográficas que fornecemos ao final de cada volume. 2.2.5 Roteamento por estado de enlace O roteamento por estado de enlace foi o substituto do roteamento com vetor de distância na ARPANET. Esta técnica pode ser descrita com base nos cinco passos a seguir, os quais cada roteador deve executar: » Conhecimento dos vizinhos: cada roteador deve enviar para seus vizinhos um pacote do tipo HELLO e aguardar respostas contendo identificadores de cada nó alcançado. » Medição do custo do enlace: esta tarefa leva em conta, usualmente, o retardo para um pacote ir de um roteador até um de seus vizinhos. A forma mais simples de medir este retardo consiste em enviar um pacote do tipo ECHO, marcado com um timbre de hora de envio, o qual deve ser imediatamente respondido pelo roteador de destino. De volta à origem, obtém-se o tempo de ida e volta e, dididindo-se por dois, estima-se o retardo procurado. » Criação de pacotes de estado de enlace: no primeiro campo do pacote, colocase um identificador do roteador de origem, seguido por um número de sequência, pela idade e por uma lista de vizinhos. Esses pacotes devem ser criados, isto é, atualizados, periodicamente. » Envio dos pacotes de estado de enlace a todos os outros roteadores: este passo é executado, basicamente, por meio do algoritmo de inundação. Os campos número de sequência e idade são, então, utilizados para evitar problemas como os que descrevemos na seção 2.2.3. O número de sequência é incrementado a cada salto e usado para que os roteadores saibam quando receberam cópias e possam descartá-las; a idade é decrementada a cada salto, para que os pacotes não fiquem transitando por tempo indefinido na rede. » Cálculo do caminho mais curto até cada um dos roteadores: após o envio dos pacotes de estado de enlace, grafos das subredes poderão ser criados. O cálculo propriamente dito do caminho mais curto entre cada par de roteadores é obtido pela execução do algoritmo de Dijkstra. Os resultados obtidos são copiados para as tabelas de repasse e a operação normal da rede pode ser retomada. O roteamento pode estado de enlace é amplamente empregado em redes de computadores reais. O protocolo OSPF, que estudaremos noutra seção e que é bastante utilizado na Internet, é baseado nesta técnica. 38
- 39. Redes de Computadores 2.2.6 Roteamento hierárquico Em seções anteriores, já conversamos um pouco sobre roteamento hierárquico e percebemos o quanto esta técnica é importante, quando se trata de roteamento em redes de grande porte. Você pode imaginar uma rede com milhões de nós executando algum dos algoritmos que descrevemos nas seções anteriores!? Imagine o tempo e a largura de banda gastos para que cada nó aprendesse sobre seus vizinhos e, de alguma forma, transmitisse essas informações para todos os outros nós da rede... além do mais, seriam necessárias memórias imensas para armazenar todos os dados gerados. O roteamento hierárquico existe para evitar tudo isso. A ideia principal é dividir os roteadores em regiões, conforme apresentado na Figura 2.6. Dois níveis hierárquicos são formados (o números de níveis pode ser maior, segundo a quantidade de nós da rede). Cada roteador precisa, portanto, conhecer os detalhes do encaminhamento apenas quando o destino se encontrar na mesma região que a sua; quando o roteador de destino estiver noutra região, o roteador de origem preocupase apenas em enviar os dados para “fora” de sua região por meio de um roteador específico. Daí por diante, o trabalho é repassado aos roteadores que se encontrarão ao longo do percurso. Figura 2.6 – Roteamento hierárquico O procedimento descrito proporciona tabelas de roteamento bem menores. Na Figura 2.6, por exemplo, que contém 17 roteadores, a tabela de K deveria ter 16 linhas, caso não se utilizasse o roteamento hierárquico. Considerando a estrutura em regiões, a tabela de K teria apenas 6 linhas: 4 linhas informando como enviar pacotes aos nós que também estão na região 3 e 4 linhas informando como enviar pacotes às outras 4 regiões (por meio dos nós H e/ou L). 2.2.7 Roteamento por difusão e por multidifusão Em algumas aplicações, o envio de uma mesma mensagem a todos os hosts pertencentes a uma rede se faz necessário. Isso configura o que chamamos de difusão (broadcasting) e é comum em casos em que se deseja, por exemplo, enviar relatórios ou transmitir um programa de rádio. Uma primeira forma de realizar o roteamento nesta situação é considerar que cada pacote deve ser enviado “individualmente” a cada um dos 39
- 40. Redes de Computadores destinos. Este método desperdiça largura de banda e requer que a origem tenha uma lista completa de todos os destinos. Uma segunda possibilidade (um tanto natural) é recorrer ao algoritmo de inundação, o qual precisará enfrentar, também nesse contexto, os mesmos problemas que já descrevemos anteriormente. O terceiro método é conhecido como roteamento por vários destinos, que requer a inclusão de uma espécie de mapa no cabeçalho do pacote, indicando os destinos em que ele precisa ser entregue. Quando um roteador recebe um desses pacotes, ele seleciona as portas de saída que levam aos destinos desejados e repassa o pacote apenas para as saídas selecionadas. O quarto método define o que chamamos de árvore de amplitude, que é similar à árvore de escoamento (definida na seção 2.2.1) e que corresponde um subconjunto da subrede que inclui todos os roteadores, mas não contém nenhum loop. Quando um roteador receber um pacote de difusão de entrada, se ele conhecer uma árvore de amplitude, ele copiará o pacote em todas as linhas que fazem parte da árvore, exceto naquela pela qual o pacote chegou. Você Sabia? Mesmo quando um roteador nada sabe sobre suas árvores de amplitude, ele pode encaminhar eficientemente pacotes de difusão? Isso é proporcionado pelo que chamamos de encaminhamento pelo caminho inverso. Faça uma busca na Internet e noutras fontes bibliográficas e aprenda mais sobre esta importante técnica! Noutros cenários, é necessário enviar mensagens a grupos com um grande número de hosts, mas não a todos os hosts de uma rede. Isso caracteriza a mutidifusão (multicasting). Aqui, não é eficiente utilizar os mesmos métodos empregados na difusão, pois um grande número de nós que não estão interessados na mensagem a receberia; realizar o encaminhamento individual também não funcionaria. Portanto, são necessárias técnicas específicas que, normalmente, requerem o gerenciamento de grupos identificando os hosts que receberão determinada mensagem. Considere, por exemplo, a Figura 2.7. Os nós são identificados como pertencentes ao grupo 1 e/ou ao grupo 2 (ou a nenhum dos grupos). Na parte (b) da figura, apresenta-se uma árvore de amplitude para o roteador mais à esquerda. Quando este roteador recebe algum pacote de multidifusão destino aos nós do grupo 1, os nós que não fazem parte deste grupo são “removidos” da árvore original; diz-se que a árvore é “podada”, dando origem ao que se denomina árvore de multidifusão (parte (c)), por meio da qual o pacote pode ser encaminhado. Algo semelhante acontece no encaminhamento de um pacote de multidifusão ao grupo 2. 40
- 41. Redes de Computadores Figura 2.7 – (a) Uma rede. (b) Uma árvore de amplitude correspondente ao roteador mais 1ª esquerda. (c) Uma árvore de multidifusão correspondente ao grupo 1. (d) Uma árvore de multidifusão correspondente ao grupo 2 2.2.8 Roteamento para hosts móveis Nos últimos anos, redes de computadores com hosts móveis estão se tornando cada vez mais comuns. Nestes cenários, algumas considerações iniciais precisam ser realizadas do ponto de vista de roteamento, a começar pela necessidade de localizar o host antes de enviar dados até ele. Um modelo que se costuma considerar na abordagem deste problema é apresentado na Figura 2.8. Nela, observa-se uma rede WAN, de grande abrangência geográfica, a qual estão ligadas redes menores, incluindo células sem fio. Aqui, partimos do princípio de que cada host móvel possui um local de origem que não muda; sua identidade, neste local de origem, é conhecida pelo elemento representado na figura e denominado agente local. Na figura, também é ilustrado um agente externo, responsável por “tomar conta” de hosts oriundos de outras redes e que estão fazendo uma visita. Quando um agente externo percebe um host visitante, ele entra em contato com o agente do local de onde o host se origina, a fim de realizar uma espécie de registro. Figura 2.8 – Uma WAN a qual estão conectadas LANs, MANs e células sem fio O processo de roteamento para um host móvel A que se encontra fora da sua base é descrito de forma resumida a seguir. Quando um host B deseja enviar algo para o host 41
- 42. Redes de Computadores A, o roteamento é realizado convencionalmente desde B até o agente local de A. O agente local sabe que A está visitando outra rede e envia, usando um procedimento chamado tunelamento, os pacotes recebidos de B para o agente externo da rede em que A se encontra; os pacotes são, então, entregues a A. Logo após, o agente local informa ao host B o local que A está visitando, a fim de que os próximos pacotes sejam enviados diretamente de B para o agente externo e sejam, finalmente, entregues a A sem a necessidade de passar pelo seu agente local. É claro que o processo explicado envolve uma série de complexidades que fogem ao escopo deste material. Um cenário ainda mais complexo é aquele em que, além dos hosts, os próprios roteadores são móveis. Em casos como este, um mesmo nó corresponde, normalmente, a um host e também a um roteador, o que caracteriza o que chamamos de rede ad hoc ou MANETs (Mobile Ad Hoc NETworks). Apenas para o nosso conhecimento, o principal algoritmo de roteamento em redes desse tipo é o AODV (Ad hoc On-demand Distance Vector). Dica Peer-to-Peer ou P2P é uma arquitetura de sistemas distribuídos que se caracteriza pela descentralização das funções na rede; cada nó pode realizar tanto funções de servidor quanto de cliente. Certamente, você já utilizou aplicações que trabalham desta forma para fazer o download de arquivos que se encontram nos computadores de outros usuários e, também, para compartilhar os seus arquivos. Encontre softwares que servem de interface para este tipo de serviço e descubra detalhes sobre como o roteamento é realizado em cenários como esse. 2.3 A Camada de Rede na Internet Nesta seção, estudaremos os detalhes do funcionamento da camada de rede na Internet. Como não poderia deixar de ser, o nosso principal “astro” quando se trata desse assunto é o IP (Internet Protocol). Falaremos sobre a versão usual deste protocolo e conversaremos um pouco sobre o IPv6. Além disso, abordaremos algumas questões relacionadas aos sistemas autônomos e às técnicas de roteamento utilizadas neste cenário. 2.3.1 O protocolo IP Para que possamos nos situar bem, antes de começarmos a falar sobre o IP propriamente dito, é importante lembrarmos que há três componentes principais na camada de rede na Internet. O primeiro deles é o componente de roteamento, sobre o qual iniciamos o estudo na seção 2.2; os outros componentes são o protocolo IP e o ICMP, que serão investigados a partir de agora. Iniciaremos nossa conversa considerando o IPv4, ou simplesmente IP, que é a versão mais usada do protocolo. Mais à frente, falaremos sobre o IPv6, versão proposta como substituta do IPv4. O formato do datagrama IP (é esse o nome que recebe um pacote da camada de rede) é apresentado na Figura 2.9. Veremos que o conhecimento de cada um dos campos apresentados ajuda bastante no entendimento acerca do funcionamento deste protocolo. No datagrama, o primeiro campo (4 bist) corresponde à versão, que indica como o roteador deve interpretar o restante das inforamações (versões diferentes têm formatos de datagrama diferentes). Como em função da inclusão (ou não) de opções o cabeçalho 42
- 43. Redes de Computadores do datagrama pode possuir diferentes tamanhos, é necessário o campo comprimento do cabeçalho. Tipicamente, o cabeçalho possui 20 bytes. Figura 2.9 – Formato do datagrama IP O campo ToS (Type of Service, tipo de serviço) permite que se indique se o datagrama requer algum tratamento especial, como transmissão em tempo real ou confiabilidade. O campo comprimento do datagrama indica o tamanho do datagrama em bytes (cabeçalho mais dados), cujo máximo é 65.535. Observamos que, normalmente, os datagramas não são maiores que 1.500 bytes (descubra o motivo disso!). Os campos identificador, flags e deslocamento de fragmentação têm relação com a possibilidade de fragmentação do datagrama (falaremos melhor sobre isso mais a diante). O tempo de vida (TTL) é decrementado a cada salto do datagrama e, quando chega a zero, indica que o datagrama deve ser “destruído”. O campo protocolo indica por qual protocolo da camada de transporte o datagrama IP deve ser tratado. A soma de verificação do cabeçalho auxilia um roteador na detecção de erros de bits em um datagrama IP (funciona de modo semelhante ao que explicamos quando estudamos os protocolos da camada de transporte). Quando um datagrama é criado, o endereço IP da fonte e o endereço IP do destino são inseridos no cabeçalho. No campo opções, pode-se, por exemplo, especificar o nível de segurança do datagrama, indicar o caminho completo a ser seguido, determinar uma lista de roteadores pelos quais o datagrama deve passar etc. A ideia é recorrer o mínimo possível ao uso deste campo. Finalmente, encontra-se o campo de dados, que contém o segmento da camada de transporte a ser entregue no destino. Alguns campos que descrevemos têm significado e uso bastante intuitivos. Isso não acontece, por exemplo, com os campos relacionados à fragmentação do datagrama, que merecem uma explicação um pouco mais detalhada. Quando estudarmos os protocolos da camada de enlace, veremos que um dos parâmetros que eles definem é a unidade máxima de transmissão (MTU, maximum transmission unit), isto é, a quantidade máxima de dados que um quadro pode carregar. Ao longo de uma rota, um datagrama IP pode passar por redes com MTUs distintas, o que requer que, eventualmente, este datagrama seja “quebrado” em pedaços menores chamados fragmentos. A fragmentação de um datagama, normalmente, ocorre no roteador de entrada da rede que impõe uma MTU menor; a reconstrução do datagrama ocorre no sistema final. Quando um datagrama é fragmentado, cada “pedaço” permanece com o mesmo identificador, para que, no destino, se saiba que os diversos datagramas recebidos são, na verdade, fragmentos de um datagrama único e devidamente especificado. Em cada fragmento, também são copiados os endereços da fonte e do destino e determinados os campos deslocamento de fragmentação, que indica que posições os fragmentos devem ocupar na remontagem do datagrama original, e flags, que informam quando o datagrama não deve ser fragmentado e quando um datagrama recebido representa, na verdade, o último fragmento de um datagrama que foi anteriormente “quebrado” (isso é necessário 43
- 44. Redes de Computadores para que o host tenha certeza de que o último fragmento chegou, já que a camada de rede, por si só, não oferece garantia de entrega). Dica Em http://media.pearsoncmg.com/aw/aw_kurose_network_2/applets/ip/ipfragmentation. html, encontra-se uma applet que ilustra a atribuição dos campos do cabeçalho IP referentes à fragmentação de um datagrama, quando esta operação é necessária. O usuário fornece o identificador do datagrama, o seu tamanho e a MTU da rede; o programa calcula automaticamente o deslocamento de fragmentação e os flags. Experimente! Endereçamento IPv4 A partir de agora, discutiremos o esquema de endereçamento empregado no IPv4. Bem mais do que números configurados por meio de telas simples que os sistemas operacionais apresentam, veremos que os endereços IP desempenham um papel crucial no correto desempenho das funcionalidades da camada de rede. No presente contexto, definimos interface como a fronteira entre um host e o enlace físico ao qual ele está ligado. Naturalmente, um roteador terá múltiplas interfaces, uma para cada enlace ao qual ele estiver ligado; a cada interface está associado um endereço IP. Um endereço IP tem comprimento de 32 bits (4 bytes) e, usualmente, é escrito em notação decimal separada por pontos; são apresentados quatro números decimais, cada um correspondendo a um dos 4 bytes do endereço. Como exemplo, considere o endereço 193.32.216.9. Em notação binária, este endereço é 11000001 00100000 11011000 00001001. Para todos os efeitos, cada uma das interfaces que mencionamos (seja de um host ou de um roteador) tem um endereço IP globalmente exclusivo e determinado segundo a subrede a qual a interface está conectada. Observe, por exemplo, a Figura 2.10, em que são apresentados seis hosts e três roteadores que os interconectam. As duas máquinas na parte de cima da figura possuem endereços da forma 223.1.1.xxx; o mesmo acontece com a interface do roteador a qual essas máquinas estão ligadas. Noutras palavras, as referidas interfaces possuem endereços com o mesmo prefixo. A área hachurada representa uma subrede. Isso significa que, para uma troca de dados entre as respectivas interfaces, não é necessário “atravessar” um roteador. O endereçamento IP designa um endereço a essa subrede: 223.1.1.0/24, em que a notação /24 representa o que chamamos de máscara de subrede e indica, ao mesmo tempo, o número de bits que identificam a subrede e quantos bits “sobram” para identificar as interfaces desta subrede (8 bits, neste caso). O mesmo se aplica às outras subredes apresentadas na figura. O termo subrede também é usado para fazer referência a trechos da rede que interligam dois roteadores; sendo mais claro, o “cabo” que conecta a interface de um roteador à interface de outro roteador também é uma subrede. 44
- 45. Redes de Computadores Figura 2.10 – Três roteadores interconectando seis subredes De forma geral, a atribuição de endereços na Internet se baseia na técnica conhecida como roteamento interdomínio sem classes (CIDR, classless interdomain routing). Analogamente ao que descrevemos no exemplo, os 32 bits do endereço IP são divididos em duas partes. Assim, num endereço escrito como a.b.c.d/x, x indica o número de bits na primeira parte do endereço, que corresponde ao prefixo. Normalmente, uma instituição recebe uma faixa de endereços sequenciais com o mesmo prefixo (mais tarde, isso será usado para facilitar o roteamento para máquinas que pertencem a essa instituição). Os (32 – x) bits restantes de cada endereço distinguem os equipamentos e dispositivos dentro da instituição. Antes da adoção do CIDR, utiliza-se um esquema de atribuição de endereços denominado endereçamento de classe completo. Nessa estratégia, só se permitia endereços associados a algumas classes pré-definidas. Um endereço de classe C, por exemplo, determinava x = 24, o que fazia sobrar apenas 8 bits para distinguir interfaces de uma mesma subrede. Isso significa que, no máximo, 28 – 2 = 254 interfaces poderiam ser endereçadas (2 45
- 46. Redes de Computadores endereços são reservados para uso especial). Se uma instituição desejasse mais endereços, precisaria se enquadrar na classe B, que determina x = 16 e, consequentemente, permite que 65.534 interfaces sejam endereçadas. Ora, se uma instituição tivesse mais que 254 máquinas para endereçar, ela precisaria de endereços classe B, mas, se tivesse bem menos que 65.534 máquinas, muitos endereços seriam desperdiçados (os endereços não utilizados não poderiam ser “entregues” a outra instituição). Esse foi um dos motivos que acelerou a escassez de endereços IPv4 e incentivou a introdução de estratégias como o CIDR, que aproveita melhor os endereços, e o NAT (que descreveremos mais a diante). Devemos mencionar, ainda, que o envio de um datagrama com o endereço de destino 255.255.255.255, conhecido como endereço de broadcast, faz com que todos os hosts que estão na subrede recebam este datagrama. Além disso, é importante dizermos que os blocos de endereços IP são concedidos às instituições por meio de empresas provedoras de serviços de Internet; essas empresas obtêm os endereços de uma organização sem fins lucrativos chamada Internet Corporation for Assigned Names and Numbers (ICANN). Dica Quando conhecemos um endereço IP e a máscara de subrede a qual este endereço está submetido, podemos obter o prefixo da subrede em questão. Essa tarefa é ilustrada no link http://www.netbook.cs.purdue.edu/animations/address%20masks.html, em que se encontra uma animação em flash bastante esclarecedora. Acesse já! Dica Em http://www.netbook.cs.purdue.edu/animations/forwarding%20an%20IP%20datagram. html, se encontra outra grande dica! Neste link, podemos acompanhar o caminho seguido por um datagrama IP ao longo de diversas redes e roteadores. As decisões dos roteadores com base na aplicação de máscaras de subrede são ilustradas com detalhes. Clique e veja! DHCP – Protocolo de Configuração Dinâmica de Hosts Para que um host, de fato, se conecte a uma rede, é necessário que ele receba um endereço. Essa atribuição de endereços pode ser feita de forma manual pelo responsável pela rede ou, como normalmente tem acontecido, por meio do DHCP (Dynamic Host Configuration Protocol). Além de realizar automaticamente a atribuição de um endereço IP a um host, o DHCP pode fornecer informações adicionais como a máscara de subrede, o endereço do primeiro roteador (default gateway) e o endereço do servidor de DNS local. O DHCP tem sido especialmente útil na atribuição de endereços de clientes que acessam a Internet por meio de um provedor. Se um provedor possui 2000 clientes, por exemplo, mas sabe que, em média, apenas 400 clientes estão online, ele precisa de um bloco com apenas 512 endereços, que são “emprestados” de forma dinâmica pelo DHCP. É como numa rede telefônica: uma central tem um número de circuitos menor que o número de assinantes ligados a ela, pois se presume que apenas uma parte desses assinantes desejará realizar chamadas simultaneamente. O DHCP também tem aparecido em redes domésticas. Quando se tem em casa um roteador sem fio, por exemplo, e vários PCs ou notebooks, os endereços dessas máquinas podem ser configurados via DHCP. 46 De maneira mais precisa, quando uma máquina deseja receber um endereço, ela
- 47. Redes de Computadores envia em difusão uma mensagem denominada DHCP DISCOVER (dentro de um segmento UDP para a porta 67). Um servidor DHCP que intercepta essa mensagem envia, também em difusão, uma mensagem de oferta DHCP. A máquina, então, escolhe dentre as ofertas recebidas e informa sua escolha ao servidor. Quando o servidor responde, dessa vez com a mensagem DHCP ACK, a transação está concluída e a máquina recebe o endereço por determinado tempo. NAT – Tradução de endereços na rede Quando a Internet começou a ganhar popularidade, apenas os PCs e as portas dos roteadores precisavam de endereços. Hoje, a realidade é bem diferente. A diversidade de equipamentos com interface de rede, como impressoras, telefones celulares e vídeogames, tem crescido espantosamente e encontrado um cenário em que a concessão de um endereço IP é cada vez mais difícil. O NAT (Network Address Translation) surgiu como um “remédio” para este problema, fazendo uso do que chamamos aqui de domínio de endereços privados. Essa terminologia se refere a uma rede em que os endereços têm signficado apenas para equipamentos pertencentes àquela rede. Figura 2.11 – Tradução de endereços de rede Considere, por exemplo, a Figura 2.11. Todas as interfaces da rede do lado direito da figura possuem endereços da forma 10.0.0.0/24 (o espaço de endereço 10.0.0.0/8 é uma das três porções do espaço de endereço IP reservadas a redes privadas), no entanto, para o “mundo externo”, essa rede se apresenta como um único equipamento com endereço 138.76.29.7 (observe as portas do roteador ligado à rede considerada; esse é o endereço que fica voltado para o “lado de fora”). Quando um pacote passa pelo roteador, saindo da rede, o NAT substitui o endereço IP da fonte (que só possui significado local) pelo endereço 138.76.29.7, ou seja, o endereço do lado da WAN; o número de porta de fonte é substituído por outro número de porta, gerado pelo NAT e usado como índice para uma tabela de tradução na qual os valores subtituídos ficam armazenados. Quando um pacote vem da Internet, ao passar pelo roteador, o processo descrito é invertido e, assim, saber-se-á a que 47
- 48. Redes de Computadores máquina interna à rede e em qual porta desta máquina o pacote deve ser entregue. Há alguns motivos que fazem com que certos estudiosos da Internet critiquem o NAT. O primeiro motivo é que o NAT emprega números de porta para auxiliar no endereçamento a hosts, quando, na verdade, as portas deveriam ser usadas apenas para endereçar processos. Ligado a isso, está o fato de os roteadores, com o NAT, precisarem processar pacotes até a camada quatro, quando deveriam fazê-lo apenas até a camada três. Por fim, alega-se que o viola o argumento fim a fim, uma vez que hosts deveriam falar diretamente com hosts, sem se submeter a procedimentos intermediários que alterem endereços de interfaces e números de portas. O fato é que, independentemente disso, o NAT tornou-se importante e, em alguns casos, indispensável na superação do problema da escassez de endereços de rede. Dica Em http://www.netbook.cs.purdue.edu/animations/NAT%20Concept.html, é apresentada uma animação em flash ilustrando o funcionamento do NAT. Acesse o link e compare o exemplo animado com o que você aprendeu ao longo desta seção! ICMP – Protocolo de Mensagens de Controle da Internet O funcionamento da Internet é monitorado de várias formas pelos roteadores. Sempre que acontece algum evento inesperado ou algum teste precisa ser realizado, entra em cena o ICMP (Internet Control Message Protocol). Este protocolo estabelece dezenas de mensagens de controle e auxilia na implementação de programas como o traceroute, usado no acompanhamento da rota seguida por pacotes que vão de um host a outro em qualquer lugar do mundo. Os tipos de mensagens mais importantes do ICMP são apresentados na Figura 2.12. Tipo de mensagem Descrição Destination unreachable Não foi possível entregar o pacote Time exceeded O campo Time to live chegou a 0 (zero) Parameter problem Campo de cabeçalho inválido Redirect Ensina geografia a um roteador Echo Pergunta a uma máquina se ela está ativa Echo reply Sim, estou ativa Timestamp request Igual a Echo, mas com timbre de hora Timestamp reply Igual a Echo reply, mas com timbre de hora Figura 2.12 – Os principais tipos de mensagens ICMP IPv6 Ao longo desta seção, temos mencionado a escassez de endereços que tem sido enfrentada pelo IPv4. Prevendo que, em algum momento, uma situação de escassez 48
- 49. Redes de Computadores completa de endereços ocorreria, no ínicio da década de 1990, tomou-se a iniciativa de projetar o IPv6, futuro substituto do protocolo em vigor até então. Iniciaremos a abordagem do IPv6 apresentando a estrutura do seu datagrama, que pode ser vista na Figura 2.13. Figura 2.13 – Formato do datagrama IPv6 O datagrama é iniciado com o campo versão, que contém o número 6. Em seguida, aparece o campo classe de tráfego, que desempenha uma função semelhante à do campo tipo de serviço do IPv4. O campo rótulo de fluxo permite identificar os datagramas como pertencentes a um fluxo particular para o qual o remetente requisita algum tratamento especial. O comprimento de carga útil informa o número de bytes no datagrama que se segue ao cabeçalho (já que este tem tamanho fixo de 40 bytes). O campo próximo cabeçalho indica a que protocolo de transporte o datagrama será entregue. O limite de saltos é decrementado a cada passagem por roteador e, quando chega a 0 (zero), faz o datagrama ser descartado. Os campos endereço de fonte e de destino, agora, têm 128 bits cada; com essa expansão o problema de escassez de endereços é resolvido. No IPv6, não ocorre fragmentação de datagramas. Em situações em que isso seria necessário, o datagrama é descartado e a fonte é informada sobre o ocorrido, de maneira que datagramas menores sejam criados. Somas de verificação também não são realizadas. O principal objetivo disso é fazer com que os pacotes sejam encaminhados mais rapidamente, evitando certas operações que consomem tempo e que já são realizadas por outras camadas. Dentre outras alterações que não mencionamos aqui, no IPv6, também foi concebida uma nova versão do ICMP. Uma questão crucial sobre o IPv6 é a que envolve a transição do IPv4 para a nova versão do protocolo. Nesse contexto, duas abordagens merecem destaque. A primeira delas é denominada pilha dupla (dual stack) e requer que nós IPv6 tenham, também, a capacidade de implementar o IPv4 de forma completa. Nós IPv6/IPv4 devem ter endereços dos dois tipos e, além disso, devem poder determinar a versão para a qual um nó com quem deseje se comunicar está habilitado. A dificuldade dessa abordagem é que, quando dois nós habilitados para IPv6 se comunicarem, se seus pacotes precisarem passar por nós que só implementam IPv4, alguns campos de cabeçalho serão perdidos, uma vez que não haverá, no IPv4, campos correspondentes, por exemplo, ao identificador de fluxo. A outra abordagem é conhecida como implantação de túnel (tunneling). Esse mecanismo consiste em enviar um datagrama IPv6 no campo de dados de um datagrama IPv4, o que remove a limitação descrita no parágrafo anterior. Neste caso, o trecho em que só o IPv4 é implementado é enxergado como um túnel; o endereço de destino inserido no datagrama IPv4 que dá “carona” ao IPv6 corresponde ao endereço do último nó deste túnel. A partir daí, o datagrama IPv6 volta a trafegar normalmente. 49
- 50. Redes de Computadores 2.3.2. Roteamento na Internet Após termos apresentado na seção 2.2 algoritmos de roteamento de uso geral, nesta seção, conheceremos um pouco mais sobre o roteamento na Internet. Para iniciarmos esse estudo, é importante sabermos que a Internet é formada por sistemas autônomos (AS, autonomous systems); cada AS é operado por uma empresa diferente e pode, portanto, utilizar seu próprio algoritmo de roteamento interno. Nesse contexto, classificamos os algoritmos de roteamento usados na Internet como protocolos de gateway interior, que correspondem àqueles empregados no roteamento interno num AS, e protocolos de gateway exterior, que correspondem àqueles empregados no roteamento entre ASs. OSPF – Roteamento Intra-AS na Internet O protocolo de gateway interior utilizado originalmente na Internet se chamava RIP e era baseado no algoritmo com vetor de distância. O RIP tinha sido herdado da ARPANET e funcionava bem em sistemas pequenos. Isso não acontecia quando um AS se tornava maior, tornando mais evidentes problemas como o de contagem até infinito. O OSPF foi concebido como sucessor do RIP, sendo baseado no roteamento por estado de enlace e no cálculo do caminho mais curto por meio do algoritmo de Dijkstra. Com o OSPF, um roteador transmite informações de roteamento a todos os outros roteadores que estão num AS. Como essa transmissão se dá de forma periódica, mesmo que não haja mudanças significativas no estado do enlace, o procedimento se torna mais robusto, assegurando a transferência confiável das informações e verificando se certos enlaces estão operando como esperado. Também merece destaque a segurança que é proporcionada pelo OSPF. Todas as trocas entre roteadores passam por algum tipo de autenticação, a fim de evitar que intrusos injetem informações erradas nas tabelas de repasse. O OSPF permite, também, que sejam usados vários caminhos para alcançar determinado destino, quando estão disponíveis diversas rotas com o mesmo custo. O OSPF fornece, ainda, suporte integrado para roteamento unicast e multicast e para hierarquia dentro de um único domínio de roteamento. Como dissemos, um sistema autônomo OSPF pode ser configurado hierarquicamente em áreas. Cada área tem seu próprio roteamento de estado de enlace e, dentro de cada área, um ou mais roteadores de borda de área se responsabilizam pelo roteamento de pacotes fora da área. Finalmente, uma área OSPF de um AS é escolhida para ser a área de backbone, cuja função é rotear o tráfego entre outras áreas do AS e, por meio de um roteador de borda de AS, comunicar-se com outros ASs. Tudo isso é ilustrado na Figura 2.14. 50
- 51. Redes de Computadores Figura 2.14 – A relação entre ASs, backbones e áreas no OSPF BGP – O protocolo de roteamento de gateway exterior O roteamento entre sistemas autônomos é de responsabilidade do BGP (Border Gateway Protocol). Diferentemente do OSPF, a implementação prática do BGP precisa respeitar uma série de restrições de origem, às vezes, bem mais política do que técnica. O BGP deve impedir, por exemplo, que um tráfego passe por certos ASs. Você já imaginou o que poderia acontecer se um tráfego originário do Pentágono passasse pelo Iraque!? Normalmente, essas políticas são configuradas manualmente em cada roteador BGP, não fazendo parte do procotolo propriamente dito. Um roteador BGP enxerga, basicamente, ASs e linhas que os interconectam (observe novamente a Figura 2.14). Do ponto de vista desse protocolo, as redes podem ser classificadas como (i) redes stub, que têm somente uma conexão com o grafo BGP, (ii) redes multiconectadas, que podem ser usadas para tráfego (a menos que se recusem) e (iii) redes de trânsito, dedicadas apenas ao tratamento de pacotes de terceiros. Dois roteadores BGP se comunicam por meio de conexões TCP, o que proporciona confiabilidade e “esconde” detalhes da rede que está sendo utilizada. O BGP funciona como um protocolo de vetor de distância, no entanto, em vez de manter apenas o custo para cada destino, cada roteador tem o controle de qual caminho está sendo usado e pode informar isso aos seus vizinhos. Uma consequência positiva dessa estratégia é a eliminação do problema da contagem até infinito, que atinge outros protocolos baseados em vetor de distância. Como todo o caminho ao longo do qual os dados são enviados é informado, um roteador pode verificar se a rota oferecida por algum de seus vizinhos inclui o próprio roteador de origem. 51
- 52. Redes de Computadores Aprenda Praticando Agora é chegada a hora de você praticar os conceitos aprendidos. Para isso, alguns exercícios foram selecionados para você avaliar seu entendimento do nosso segundo capítulo. Você deverá procurar entender os exercícios resolvidos e suas respectivas respostas com o intuito de consolidar os conceitos aprendidos neste capítulo. Algumas questões dos exercícios propostos fazem parte das atividades somativas que você deverá responder em relação ao capítulo 2, do Volume 2, de acordo com as orientações e prazos sugeridos pelo seu professor e tutor. Lista de exercícios propostos 1. Realize uma análise comparativa entre as redes de datagramas e as redes baseadas em circuitos virtuais. 2. Considere a rede da Figura 2.5, mas ignore os pesos nas linhas. Suponha que ela utilize a inundação como algoritmo de roteamento. Se um pacote enviado por A até D tem uma contagem máxima de saltos igual a 3, liste todas as rotas que ele seguirá. Depois, informe quantos saltos o pacote consome de largura de banda. 3. Explique o princípio de funcionamento do roteamento hierárquico. Quais são os benefícios dessa estratégia? 4. Compare e aponte as diferenças entre os algoritmos de estado de enlace e de vetor de distância. 5. Descreva como acontece o roteamento de pacotes para hosts que podem estar em trânsito, isto é, em locais que não são seus locais de origem. 6. Considere o envio de um datagrama de 2400 bytes por um enlace que tem uma MTU de 700 bytes. Suponha que o datagrama original esteja marcado com o número de identificação 258. Quantos fragmentos são gerados? Quais são os valores dos diversos campos dos datagramas IP gerados com respeito à fragmentação? 7. Suponha que, em vez de serem utilizados 16 bits na parte de rede de um endereço de classe B, tenham sido usados 20 bits. Nesse caso, quantas redes da classe B existiriam? 8. A máscara de subrede de uma rede na Internet é 255.255.240.0. Qual é o número máximo de hosts que ela pode manipular? 9. Considere um roteador que interconecta três subredes: Subrede 1, Subrede 2 e Subrede 3. Suponha que todas as interfaces de cada uma dessas três subredes tenha de ter o prefixo 223.1.17/24. Suponha também que a Subrede 1 tenha que suportar até 63 interfaces, a Subrede 2 tenha que suportar até 95 interfaces e a Subrede 3 tenha que suportar até 16 interfaces. Dê três endereços de rede (da forma a.b.c.d/x) que satisfaçam essas limitações. 10. Um roteador tem as seguintes entradas (CIDR) em sua tabela de roteamento: 52 Endereço / máscara Próximo salto 135.46.56.0/22 Interface 0 135.46.60.0/22 Interface 1 192.53.40.0/23 Roteador 1 padrão Roteador 2 Para cada um dos endereços IP a seguir, o que o roteador fará se chegar um
- 53. Redes de Computadores pacote com esse endereço? (a) 135.46.63.10; (b) 135.46.57.14; (c) 135.46.52.2; (d) 192.53.40.7; (e) 192.53.56.7 11. Visite um host que usa DHCP e obtenha seu endereço IP, máscara de rede, gateway padrão e endereço IP de seu servidor DNS local. Liste os valores encontrados. 12. Num cenário em que se utiliza o NAT (como o da Figura 2.11), explique como um roteador, mesmo recebendo pacotes com o mesmo endereço de destino, consegue entregá-los corretamente a cada um dos hosts que se encontram numa rede privada. 13. Use o programa tracert (Windows) para traçar a rota desde seu computador até vários endereços à sua escolha. Sugestão: inclua endereços que você sabe que estão noutros continentes (endereços de universidades, por exemplo) e liste os enlaces de longa distância que você descobrir. 14. Quais os principais benefícios alcançados pela utilização do IPv6 em substituição ao IPv4? Descreva as duas principais técnicas para implementação do IPv6. 15. Explique de maneira resumida o funcionamentos dos protocolos (a) OSPF e (b) BGP, utilizados para roteamento na Internet. Conheça Mais Nas últimas décadas, o uso de softwares especializados tem sido muito importante no estudo das redes de computadores. Quando se trata da camada de rede, que contém, conforme estudamos, uma série de detalhes relacionados a roteamento e endereçamento, isso se torna ainda mais importante, pois, na maioria das vezes, não temos um cenário real à nossa disposição. Dentre os softwares mais populares para simulação de ambientes de redes de computadores, encontra-se o OPNET. Este software permite, por meio de uma interface gráfica bastante agradável, a montagem de cenários bem específicos e a realização de experimentos com vistas à avaliação de desempenho de sistemas. A versão completa do OPNET é paga. No entanto, o fabricante oferece uma versão do estudante, denominada OPNET – ITGuru Academic Edition, com a qual é possível realizar uma série de simulações. Sugerimos que você acesse o link: http://www.opnet.com/university_program/itguru_academic_edition/ e faça o download do aplicativo. É necessário realizar um cadastro no próprio site e seguir uma série de passos até que o programa seja ativado e liberado para uso em seu computador. Depois de instalar o ITGuru, comece abrindo projetos já prontos, privilegiando aqueles que abordam algum aspecto relacionado à camada de rede. Há projetos sobre IP, OSPF, BGP etc. Entenda o funcionamento das simulações e discuta com seus colegas e orientadores. Atividades e Orientações de Estudos Dedique 15 horas de estudo para o Capítulo 2. Você deve organizar uma metodologia de estudo que envolva a leitura dos conceitos serão ditos apresentados neste 53
- 54. Redes de Computadores volume e pesquisas sobre o tema, usando a Internet e livros de referência. Vamos trocar idéias nos fóruns temáticos desta disciplina no ambiente virtual, pois a interação com colegas, tutores e o professor da disciplina irá ajudá-lo a refletir sobre aspectos fundamentais tratados aqui. Os chats também serão muito importantes para a interação em tempo real com o seu tutor virtual, seu professor e seus colegas. Também é importante que você leia atentamente o guia de estudo da disciplina, pois nele você encontrará a divisão de conteúdo semanal, ajudando-o a dividir e administrar o seu tempo de estudo semanal. Procure responder as atividades propostas como atividades somativas para este capítulo, dentro dos prazos estabelecidos pelo seu professor, pois você não será avaliado apenas pelas atividades presenciais, mas também pelas virtuais. Muitos alunos não acessam o ambiente e isso poderá comprometer a nota final. Não deixe que isso aconteça com você! Os assuntos abordados neste capítulo podem ser encontrados no Quiz de número 2 da disciplina de Redes de Computadores. Através do Quiz você poderá avaliar o seu próprio desempenho. Após respondê-lo, você terá o resultado de seu desempenho e conhecerá as suas deficiências, podendo supri-las nas suas próximas horas de estudo. Vamos Revisar? Neste capítulo, você estudou os aspectos mais importantes da camada de rede. Iniciamos nossa abordagem descrevendo as principais funcionalidades desta camada e discutindo a forma como as tarefas executadas por ela complementam o papel desempenhado pela camada de transporte. Em seguida, para ilustrar os diferentes serviços que a camada de rede pode oferecer, apresentamos os conceitos de redes de datagramas e de redes de circuitos virtuais. A primeira dessas classes tem como principal exemplo a Internet, em os pacotes são transmitidos sem o estabelecimento prévio de uma conexão. Como exemplos de redes CV, podemos citar o ATM, o Frame Relay e o MPLS. Ainda na introdução do capítulo, apresentamos os fundamentos do processo de roteamento. Discutimos como funciona uma tabela de repasse e descrevemos a arquitetura básica de um roteador. Na seção 2.2, iniciamos o estudo dos algoritmos de roteamento propriamente ditos. Dentre os conceitos mais gerais, estudamos o princípio de otimização e o roteamento pelo camiho mais curto (Dijkstra). Em seguida, abordamos os algoritmos de inundação, de vetor de distância e por estado de enlace, e discutimos técnicas de roteamento hierárquico, difusão, multidifusão e para hosts móveis. A análise das principais características e das restrições de cada uma dessas técnicas forneceu, certamente, uma ampla visão sobre o papel do roteamento na camada de rede. Na última parte do capítulo, estudamos a camada de rede na Internet. Iniciamos apresentando o protocolo IP, com ênfase no formato do seu datagrama e nas questões de endereçamento. Discutimos, ainda, outros protocolos e técnicas fundamentais para o bom funcionamento da camada de rede na Internet, como, por exemplo, o DHCP e o NAT. Finalizamos o estudo do IP com uma breve discussão sobre o IPv6, a versão mais recente do protocolo. Com o estudo dos protocolos OSPF e BGP, destinados, respectivamente, ao roteamento dentro de um sistema autônomo e entre sistemas autônomos, concluímos este capítulo. 54
- 55. Redes de Computadores Capítulo 3 – Internet, Intranet e Extranet Vamos conversar sobre o assunto? Caro(a) aluno(a), Após os dois capítulos iniciais deste volume, em que nos concentramos no estudo das camadas de transporte e de rede, teremos uma conversa mais rápida e sem a presença de tantos protocolos e algoritmos... O assunto que abordaremos, entretanto, não possui menor importância, pois nos ajudará a nos situarmos ainda melhor no cenário das grandes redes de computadores. Para iniciarmos a nossa conversa, é interessante fazermos uma rápida reflexão sobre o que, hoje, as redes de computadores nos oferecem. Quando realizamos atividades simples, como, por exemplo, o envio de um comunicado por e-mail ou a busca de uma informação numa página da Web, na maioria das vezes, não nos damos conta de como coisas como essas facilitam a nossa vida; mais ainda, não nos damos conta de como a vida, antes dessas possibilidades, era bem mais complicada. O fato de podermos, por meio de uma grande rede, trocar dados com máquinas que estão a milhares de quilômetros de distância tem relação com uma “velha” conhecida nossa, a Internet. Temos falado o tempo todo sobre ela e, aqui, utilizaremos o seu conceito para conversarmos sobre outros dois importantes termos: Intranet e Extranet. Uma Intranet está relacionada ao oferecimento de serviços como os que exemplificamos, mas de maneira restrita, apenas no âmbito de uma instituição, com o objetivo principal de facilitar os processos corporativos que estao presentes ali. Se você já tiver trabalhado, talvez tenha tido a oportunidade de, na sua empresa, acessar páginas com avisos ou utilizar canais específicos para reservas de recursos e recebimento de arquivos. Esse é o contexto em que se insere uma Intranet. Uma Extranet, por sua vez, funciona como uma extensão da Intranet, sendo acessível via Internet, de qualquer lugar do mundo. A ideia, nesse caso, é melhorar a comunicação não apenas entre os funcionários que estiverem numa instituição, mas incrementar também os processos entre a instituição e o mundo externo. Esperamos que você goste deste ligeiro bate-papo e que possa aprender ainda mais sobre cada cenário e sobre as facilidades proporcionadas por eles! Vamos em frente! 3.1 Internet Como dissemos no início deste capítulo, a Internet já é uma “velha” conhecida nossa... Já conhecemos muitos dos seus protocolos e muitas das suas características. Nesta seção, privilegiaremos a história da Internet e os aspectos que nos ajudarão a distingui-la de outros tipos de redes. Primeiro, é importante que saibamos que a Internet é, na verdade, um vasto conjunto de redes, o qual não foi planejado e que, hoje, não é controlado de forma central por ninguém. Sua história começou da década de 1950, quando, no auge da 55
- 56. Redes de Computadores guerra fria, o Departamento de Defesa dos Estados Unidos preocupava-se em ter uma rede de comunicações que pudesse sobreviver a uma guerra nuclear. Essa necessidade culminou com a criação de uma organização de pesquisa de defesa, a ARPA (Advanced Research Projects Agency), a qual apoiou o desenvolvimento e a implentação do que podemos chamar de “embrião” da Internet, a ARPANET. Com o tempo, a ARPANET se consolidou como uma rede que interligava diversas universidades e centros de pesquisa norte-americanos, permitindo que cientistas de todo o país compartilhassem dados e trabalhassem juntos nos seus projetos. O contínuo crescimento da rede, com a inclusão de novas instituições, e o interesse de organizações comerciais em participar do que estava se desenvolvendo fez com que o Estado percebesse que não poderia financiar para sempre algo de porte tão grande. Ao longo das décadas de 80 e 90, noutros países, redes nacionais de pesquisa também foram sendo criadas e interligadas. Há vários anos, a Internet deixou de ser um reduto de pesquisadores ligados às universidades, ao governo e à indústria. Em particular, com o surgimento da WWW (World Wide Web), a realidade foi modificada e atraiu novos e diferentes usuários. O acesso desses usuários à grande rede foi possível (e, até hoje, continua assim!) graças a empresas denominadas provedores de serviços de Internet (ISP – Internet Service Providers) que, normalemte, exploram a infra-estrutura de um sistema de telecomunicações pré-instalado (como a do sistema telefônico, por exemplo) e empregam tecnologias como a DSL e o Cable Modem. Figura 2.15 – Número de usuários da Internet a cada 100 habitantes 3.2 Intranet Uma Intranet corresponde, basicamente, a uma rede de comunicação internet de uma instituição, relacionada aos sistemas corporativos de informações. Por meior da montagem de uma estrutura que “imita” a Internet, mas em escala restrita, as empresas conectam filiais, departamentos, fornecedores e conseguem, oferecendo requisitos de 56
- 57. Redes de Computadores segurança específicos, tirar proveito de serviços semelhantes aos que são oferecidos na Internet. Para montar uma Intranet, alguns componentes básicos são necessários. Dentre eles, podemos destacar: » Servidor Web: máquina que faz o papel de repositório das informações contidas na Intranet. É nesta máquina que os clientes encontram arquivos, páginas html, e-mails etc. » Protocolos: o servidor deve ser capaz de compreender os principais protocolos de comunicação de redes de computadores. Alguns desses protocolos, os quais já foram, inclusive, estudados por nós neste volume e no volume 1, são o HTTP (comunicação do browser) com o servidor, o FTP (para transferência de arquivos), o SMTP (responsável pelo envio de e-mails) e, naturalmente, o TCP e o IP. » Identificação do servidor e das estações: para que as máquinas saibam como se encontrar e se comunicar umas com as outras, é necessário que elas estejam identificadas. A realização dessa tarefa é de responsabilidade, basicamente, de dois procotolos que também já estudamos, o DNS e o DHCP. » Estações da rede: máquinas dos funcionários, nas quais, por meio de uma interface como um browser, eles podem acessar as informações colocadas à sua disposição no servidor. Figura 2.16 – Componentes básicos de uma Intranet Alguns dos benefícios do uso de uma Intranet numa empresa são: 57
- 58. Redes de Computadores » Redução de custos de impressão, papel, distribuição de softwareI, correio e processamento; » Redução de despesas com telefonemas e pessoal no suporte telefônico; » Maior facilidade e rapidez no acesso a informações técnicas e de marketing. 3.3 Extranet Rigorosamente falando, uma Intranet pode operar apenas como uma rede corporativa dentro dos limites da empresa. No entanto, na maioria das situações, é vatajoso que a Intranet esteja ligada à Internet. Num cenário como este, constitui-se o que denominamos Extranet. Um usuário que acessa a Intranet de uma empresa a partir de um computador que tem em casa está, na verdade, fazendo uso de uma Extranet. Nesta situação, em termos de desempenho, a diferença básica em comparação com o acesso feito de dentro da própria empresa fica por conta da velocidade, que dependerá da forma como o usuário acessa a Internet. A conexão da Intranet à Internet é feita, basicamente, por meio de um roteador, o qual “coordena” a passagem de dados da Internet para o interior da rede corporativa e vice-versa. Normalmente, nesta porta entre o mundo externo e a empresa, é necessária a configuração de um firewall, com o objetivo de impedir a entrada de intrusos e de dados que possam causar danos à rede da organização. O acesso de um usuário externo a informações presentes na rede interna de uma instituição também deve ser protegido por algum mecanismo de autenticação, que pode ser, por exemplo, a simples digitação de uma senha ou qualquer outro esquema de autenticação mais robusto. Figura 2.17 – Esquema de um cenário de Extranet 58
- 59. Redes de Computadores Na Figura 2.18, é apresentado um quadro comparativo entre os cenários de Internet, Intranet e Extranet. Internet Comunicação instantÂnea sim Comunicação externa Extranet sim Acesso restrito Intranet sim sim sim sim Compartilhamento de impressoras Compartilhamento de dados sim sim sim Rede local (LAN) sim sim sim Figura 2.18 – Quando comparativo entre os cenários de Internet, Intranet e Extranet Aprenda Praticando Agora é chegada a hora de você praticar os conceitos aprendidos. Para isso, alguns exercícios foram selecionados para você avaliar seu entendimento do nosso terceiro capítulo. Você deverá procurar entender os exercícios resolvidos e suas respectivas respostas com o intuito de consolidar os conceitos aprendidos neste capítulo. Algumas questões dos exercícios propostos fazem parte das atividades somativas que você deverá responder em relação ao capítulo 3, do Volume 2, de acordo com as orientações e prazos sugeridos pelo seu professor e tutor. Lista de exercícios propostos 1. Se algum te perguntasse qual a topologia da Internet, o que você responderia? 2. Faça uma pesquisa e dê exemplos de políticas que, hoje, podem ser adotadas dentro de uma instituição, a fim de gerenciar a forma como seus colaboradores utilizam os recursos proporcionados pela Intranet da empresa. 3. Faça uma busca e descubra as tecnologias que estão disponíveis para que uma empresa se conecte a Internet e permita, assim, que usuários externos a ela busquem dados e informações nos seus servidores. 4. Você já acessou a Intranet de alguma empresa a partir da sua casa? Que tipo de mecanismo de segurança foi exigido para o seu acesso? Atividades e Orientações de Estudos Dedique 4 horas de estudo para o Capítulo 3. Você deve organizar uma metodologia de estudo que envolva a leitura dos conceitos serão ditos apresentados neste volume e pesquisas sobre o tema, usando a Internet e livros de referência. 59
- 60. Redes de Computadores Vamos trocar idéias nos fóruns temáticos desta disciplina no ambiente virtual, pois a interação com colegas, tutores e o professor da disciplina irá ajudá-lo a refletir sobre aspectos fundamentais tratados aqui. Os chats também serão muito importantes para a interação em tempo real com o seu tutor virtual, seu professor e seus colegas. Também é importante que você leia atentamente o guia de estudo da disciplina, pois nele você encontrará a divisão de conteúdo semanal, ajudando-o a dividir e administrar o seu tempo de estudo semanal. Procure responder as atividades propostas como atividades somativas para este capítulo, dentro dos prazos estabelecidos pelo seu professor, pois você não será avaliado apenas pelas atividades presenciais, mas também pelas virtuais. Muitos alunos não acessam o ambiente e isso poderá comprometer a nota final. Não deixe que isso aconteça com você! Os assuntos abordados neste capítulo podem ser encontrados no Quiz de número 3 da disciplina de Redes de Computadores. Através do Quiz você poderá avaliar o seu próprio desempenho. Após respondê-lo, você terá o resultado de seu desempenho e conhecerá as suas deficiências, podendo supri-las nas suas próximas horas de estudo. Vamos Revisar? Neste capítulo, você estudou os conceitos mais importantes relacionados à Internet, Intranet e Extranet. Em relação à Internet, você pode conhecer um pouco de história e perceber que, atualmente, a “grande rede” possui um perfil bem diferente daquele que tinha quando foi iniciada. Você também aprendeu o básico sobre Intranet e teve a oportunidade de conhecer a grande utilidade e economia que essa tecnologia representa para os diversos tipos de instituições; você foi apresentado a alguns dos componentes necessários para implementar uma Intranet e percebeu que, talvez, você até já tenha utilizado uma Intranet sem perceber. Quando Intranet e Internet se unem, chegamos a um cenário de Extranet. Pesquise mais sobr esses assuntos e reflita sobre a importância que eles têm para sua formação nesta disciplina e no curso! 60
- 61. Redes de Computadores Referências (ROSS e KUROSE, 2005) ROSS, Keith W. ; KUROSE, James F. Redes de Computadores e a Internet. Pearson Brasil, 2005. (SALTZER et al. 1984) (SOARES et. al.) LEMOS, COLCHER, 2001) Soares, L. F. G.; LEMOS, G e COLCHER S. Redes de Computadores: das LANs, WANs às redes ATM. (Tanembaum, 2003) Tanembaum Andrew. Redes de Computadores. Campus, 2003. (TORRES, 2002) TORRES G. Redes de Computadores: Curso Completo. Editora Axcel Books, 2002. 61
- 62. Redes de Computadores Considerações Finais Olá, cursista! Esperamos que você tenha aproveitado este segundo volume da disciplina de Redes de Computadores. No próximo volume, nós nos dedicaremos ao estudo das redes locais e investigaremos os detalhes da camada de enlace de dados e da camada física. Aprenderemos, também, os diversos conceitos e tecnologias relacionados às redes sem fio. Com isso, poderemos entender algumas minúcias que “ficaram no ar” e complementar o conhecimento adquirido até agora. Como diversos computadores conseguem transmitir dados por um mesmo cabo sem que essas dados se misturem? Como uma máquina lança sinais por uma antena e esses sinais chegam “intactos” na antena de outra máquina? Certamente, você já ouviu falar nos endereços MAC... Para que eles servem? Bom, você pode até ir pensando nas respostas a essas perguntas, mas o nosso papo sobre isso só começa no próximo volume! Aguardamos sua participação! Até lá e bons estudos! 62
- 63. Redes de Computadores Conheça os Autores Juliano Bandeira Lima Brasileiro, nascido em Recife-PE em 11 de maio de 1980, recebeu o título de Engenheiro Eletricista (modalidade Eletrônica) pela Universidade Federal de Pernambuco em 2002. Pela mesma instituição, tornou-se Mestre e Doutor em Engenharia Elétrica nos anos de 2004 e 2008, respectivamente. Em 2009, tornou-se professor da Escola Politécnica (POLI) da Universidade de Pernambuco (UPE) e, desde 2006, é professor do curso de Sistemas de Informação da Faculdade Integrada do Recife (Estácio / FIR). Realizou, em 2007, estágio no exterior, na Escola de Matemática e Estatística da Carleton University, em Ottawa (Canadá). Atua, desde 2010, como colaborador da equipe do programa de formação continuada à distância em Mídias na Educação, da Universidade Federal Rural de Pernambuco. É membro efetivo da Sociedade Brasileira de Telecomunicações (SBrT), pesquisador do Grupo de Pesquisa em Redes e Comunicações (POLI/UPE) e professor do Programa de Pós-graduação em Engenharia de Sistemas (UPE). Com pesquisas realizadas nas áreas de Processamento de Sinais, Segurança da Informação e Matemática Aplicada e Computacional, é autor de diversos artigos em congressos e periódicos, tendo atuado também como revisor técnico, participante de bancas e comissões julgadores em concursos e trabalhos de conclusão de curso e como orientador de alunos em diferentes níveis. Desempenha outras atividades relacionadas à produção musical, literária e de desenho artístico e publicitário. Obionor de Oliveira Nóbrega Obionor de Oliveira Nóbrega é formado em Processamento de Dados pelo Centro de ensino Superior do Pará, especialista em Tecnologia da Informação e Mestre em Ciência da Computação pela Universidade Federal de Pernambuco. Possui também MBA em Finanças Corporativas e atualmente é doutorando do Centro de Informática da UFPE. 63