From Duke of DevOps to Queen of Chaos - Api days 2018
Download as PPTX, PDF•1 like•693 views

Christophe Rochefolle discusses the evolution of DevOps and the importance of chaos engineering in managing complex IT systems, particularly in the context of high availability demands from the European management. He emphasizes the need for error budgets, observability, and proactive testing to improve service reliability while also addressing the complexities of modern software development. The presentation highlights the utility of chaos engineering as a method to test system resilience against unexpected failures in production environments.





























From Duke of DevOps to Queen of Chaos - Api days 2018
- 1. From Duke of DevOps To Queen of Chaos APIdays.io Paris December 11 & 12, 2018 Christophe ROCHEFOLLE Director Operational Experience @OUI.sncf @crochefolle
- 2. Experienced IT executive providing tech & organization to improve #quality & #agility for IT systems, #ChaosEngineering fan Co-author of French DevOps book Who am I ?
- 3. French National Railway Company Founded in 1938. First e-Commerce website in France IT Leader in mobility, transform your journey into an amazing experience Where is my playground ? 99,997% SLA availability OUR RECORD 39 TICKETS SOLD by SECOND SPEED RECORD 574.8 KM/H
- 4. 2008 Andrew Shafer and Patrick Debois helds a "birds of a feather" session in 'Agile Toronto' 2009 “DevOpsDays” conference started in Belgium by Patrick Debois, and term “DevOps" coined 2009 “10 Deploys per Day at Flickr” talk by John Allspaw and Paul Hammond in “Velocity” conference 2009 In “Velocity” conference, Andrew Clay coined "Wall of confusion" 2009 Mike Rother wrote Toyota Kata and defined 'Improvement Kata' 2010 “Continuous Delivery” book from Jez Humble and David Farley, defined "deployment pipeline" 2011 “The Phoenix Project” book from Gene Kim and Kevin Behr 2011 Amazon deploys to production every 11.6 seconds 2014 “DevOps for Dummies” book by Sanjeev Sharma 2014 Etsy deploys more than 50 times a day 2016 “The DevOps Handbook” book by Gene Kim and Jez Humble 2016 First “DevOpsREX” conference in Paris 2018 “Mettre en oeuvre DevOps – 2nd Edition” book by Alain Sacquet and me 2008 2010 2011 2014 2016 2018 DevOps 2009
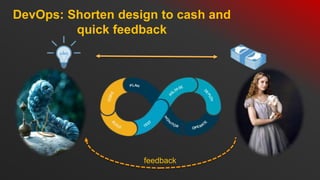
- 5. DevOps: Shorten design to cash and quick feedback feedback
- 6. Duke of DevOps Time is money. Your TTM rocks ! You have a master in CI/CD
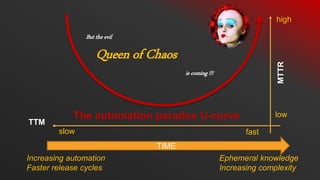
- 7. Queen of Chaos But the evil is coming !!! TIME TTM MTTR slow fast low high Increasing automation Faster release cycles Ephemeral knowledge Increasing complexity The automation paradox U-curve
- 8. For the first time, availability is the main concern for IT European management, before security. Source: Master of Machines III
- 9. Real life Focus was on the left side CI/CD Test automation Application Lifecycle Management Artifact management IaaS / PaaS / CaaS Deployment
- 11. We need new ways to develop reliability concern for our teams
- 12. …(an) error budget provides a clear, objective metric that determines how unreliable the service is allowed to be… SRE Error budget
- 13. • paying off some technical debt • improve the logging to ease support • add some additional integration or end-to-end tests • do those first steps to enable blue/green deployments • implement service mesh But, when was the last time that your product owner willingly added any of those technical stories to the next sprint? Why having Error budget ? SRE Error budget
- 14. Where to start ? 1. Convert unavailability to cash 2. Define Service Level Objective with business team 3. Define Error budget Availability = successful requests / (successful request + failed requests) A failed request can be: 1. A 500 response, due to some bug. 2. No response, due to the service being down. 3. A slow response: if the client gives up before the response is available, it is as good as no response. 4. Incorrect data, due to some bug. Error budget = (1 - availability) = failed requests / (successful requests + failed requests) So if a service SLO is 99.9%, it has a 0.01% error budget. If the service is serves one million request per quarter, the error budget tells us that it can fail up to ten thousand times. SRE Error budget
- 15. SRE Error budget How to use it ? Company agreement: Teams may no longer make any new release without spending time improving the reliability of the service when error budget is 0. In fact, they better do improvement before it.
- 16. We need new ways to know what f$$$ happens in production
- 17. Monitoring systems have not changed significantly in 20 years and has fallen behind the way we build software. Our software is now large distributed systems made up of many non- uniform interacting components while the core functionality of monitoring systems has stagnated. Monitoring is dead @grepory, Monitorama 2016
- 18. Why we need observability? Observability Complexity is exploding everywhere, but our tools are designed for a predictable world. • Can you understand what’s happening inside your code and systems, simply by asking questions using your tools? • Can you answer any new question you think of, or only the ones you prepared for? • Having to ship new code every time you want to ask a new question … SUCKS.
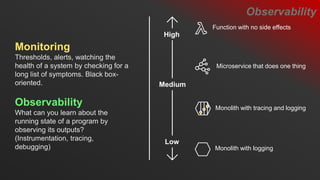
- 19. Low Medium High Microservice that does one thing Function with no side effects Monolith with logging Monolith with tracing and logging Monitoring Thresholds, alerts, watching the health of a system by checking for a long list of symptoms. Black box- oriented. Observability What can you learn about the running state of a program by observing its outputs? (Instrumentation, tracing, debugging) Observability
- 20. What do we want ? a system is observable when your team can quickly and reliably track down any new problem with no prior knowledge. Observability
- 21. Where to start ? Observability • Rich instrumentation • Events, not metrics • No aggregation • Few dashboards • Test in production Internal state from software Wrap every network call, every data call Structured data only Arbitrarily wide events mean you can amass more and more context over time. Use sampling to control costs and bandwidth. Aggregates destroy your precious details. We need MORE detail and MORE context. Dashboard focus on specific known possible failure. We need to explore raw data to discover what we don’t know. If you already know the answer, do self-healing ! Software engineers spend too much time looking at code in elaborately falsified environments, and not enough time observing it in the real world.
- 22. Need more information ? https://www.d2si.io/observabilite Follow @mipsytipsy engineer/cofounder/CEO “the only good diff is a red diff”
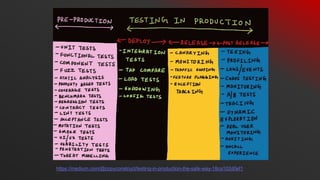
- 23. We need shit-right testing RIGHT LEFT
- 25. The performance of complex systems is typically optimized at the edge of chaos, just before system behavior will become unrecognizably turbulent. Chaos Engineering —Sidney Dekker, Drift Into Failure
- 26. How much confidence we can have in the complex systems that we put into production? Why do we need Chaos Engineering ? Chaos Engineering With so many interacting components, the number of things that can go wrong in a distributed system is enormous. You’ll never be able to prevent all possible failure modes, but you can identify many of the weaknesses in your system before they’re triggered by these events.
- 27. Queen of Chaos So, to fight the evil Chaos Engineering
- 28. Chaos engineering is the discipline of experimenting on a distributed system in order to build confidence in the systems capacity to withstand turbulent conditions in production Principles of Chaos Engineering Chaos Engineering
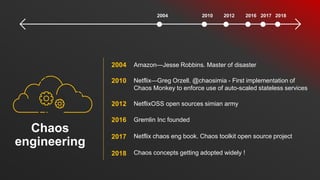
- 29. 2004 Chaos engineering 2010 2012 2016 2017 2018 2004 2010 2012 2016 2017 2018 Amazon—Jesse Robbins. Master of disaster Netflix—Greg Orzell. @chaosimia - First implementation of Chaos Monkey to enforce use of auto-scaled stateless services NetflixOSS open sources simian army Gremlin Inc founded Netflix chaos eng book. Chaos toolkit open source project Chaos concepts getting adopted widely !
- 30. Where to start ? Chaos Engineering Hypothesis testing We think we have safety margin in this dimension, let’s carefully test to be sure In production Without causing an issue 1. Start by defining ‘steady state’ as some measurable output of a system that indicates normal behavior. 2. Hypothesize that this steady state will continue in both the control group and the experimental group. 3. Introduce variables that reflect real world events like servers that crash, hard drives that malfunction, network connections that are severed, etc. 4. Try to disprove the hypothesis by looking for a difference in steady state between the control group and the experimental group.
- 31. • Simulating the failure of an entire region or datacenter. • Partially deleting Kafka topics over a variety of instances to recreate an issue that occurred in production. • Injecting latency between services for a select percentage of traffic over a predetermined period of time. • Function-based chaos (runtime injection): randomly causing functions to throw exceptions. • Code insertion: Adding instructions to the target program and allowing fault injection to occur prior to certain instructions. • Time travel: forcing system clocks out of sync with each other. • Executing a routine in driver code emulating I/O errors. • Maxing out CPU cores on an Elasticsearch cluster. Injecting Chaos Chaos Engineering
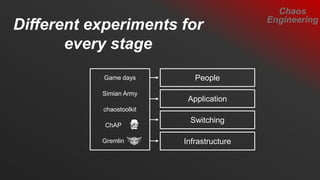
- 32. Different experiments for every stage Chaos Engineering Infrastructure Switching Application PeopleGame days Simian Army chaostoolkit ChAP Gremlin
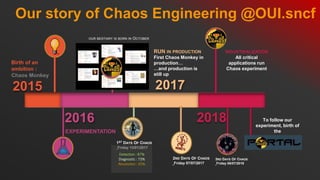
- 33. Our story of Chaos Engineering @OUI.sncf 2015 2016 2018 Birth of an ambition : Chaos Monkey EXPERIMENTATION INDUSTRIALIZATION All critical applications run Chaos experiment 2017 OUR BESTIARY IS BORN IN OCTOBER 1ST DAYS OF CHAOS Detection : 87% Diagnostic : 73% Resolution : 45% RUN IN PRODUCTION First Chaos Monkey in production… …and production is still up 2ND DAYS OF CHAOS 3RD DAYS OF CHAOS To follow our experiment, birth of the
- 34. https://days-of-chaos.slack.com Paris Chaos Engineering Meetup http://meetu.ps/c/3BMlX/xNjMx/f https://chaosengineering.slack.com http://days-of-chaos.com/ https://medium.com/paris- chaos-engineering- community
- 35. SRE Error Budget Observability Test in production Chaos Engineering Continuous Quality CI/CD Test automation Application Lifecycle Management Artifact management IaaS / PaaS / CaaS Deployment
- 36. Thank you And Bon appetite !!!
Editor's Notes
- #14: Wouldn’t it be nice to spend the next sprint or two paying off some of that technical debt that your project had accrued? Wouldn’t it be nice to improve the logging to ease support? Or add some additional integration or end-to-end tests? Or maybe do those first steps to enable blue/green deployments? But, when was the last time that your product owner willingly added any of those technical stories to the next sprint?
- #34: Zoom la prochaine, comment on y est passé