Typesafe spark- Zalando meetup
Download as PPTX, PDF•2 likes•547 views

This document discusses Typesafe's Reactive Platform and Apache Spark. It describes Typesafe's Fast Data strategy of using a microservices architecture with Spark, Kafka, HDFS and databases. It outlines contributions Typesafe has made to Spark, including backpressure support, dynamic resource allocation in Mesos, and integration tests. The document also discusses Typesafe's customer support and roadmap, including plans to introduce Kerberos security and evaluate Tachyon.





















![Dynamic Allocation
Connecting to the cluster manager:
Executor number adjust logic calls sc.requestTotalExecutors which calls
the corresponding method in CoarseGrainedSchedulerBackend ( Yarn,
Mesos scheduler classes extend it ) which does the actual executor
management.
• What we did is provide the appropriate methods to Mesos
CoarseGrainScheduler:
def doKillExecutors(executorIds: Seq[String])
def doRequestTotalExecutors(requestedTotal: Int)
24](https://image.slidesharecdn.com/typesafesparkibm20160112-160113133153/85/Typesafe-spark-Zalando-meetup-24-320.jpg)










Typesafe spark- Zalando meetup
- 1. The Typesafe Reactive Platform and Apache Spark: Experiences, Challenges and Roadmaps Stavros Kontopoulos, MSc
- 2. Fast Data and Typesafe’s Reactive Platform
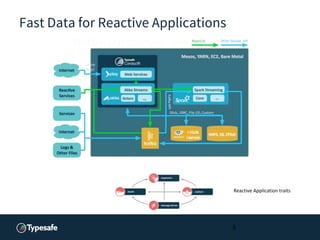
- 3. Fast Data for Reactive Applications Typesafe’s Fast Data Strategy • Reactive Platform, Fast Data Architecture This strategy aims different market needs . • Microservice architecture with an analytics extension • Analytics oriented based setup where core infrastructure can be managed by mesos-like tools and where Kafka, HDFS and several DBs like Riak, Cassandra are first class citizens. 3
- 4. Fast Data for Reactive Applications Reactive Platform (RP): • Core elements: Play, Akka, Spark. Scala is the common language. • ConductR is the glue for managing these elements. Fast Data Architecture utilizes RP and is meant to provide end-to-end solutions for highly scalable web apps, IoT and other use cases / requirements. 4
- 5. Fast Data for Reactive Applications 5 Reactive Application traits
- 6. Partnerships
- 7. Fast Data Partnerships • Databricks •Scala insights, backpressure feature • IBM •Datapalooza, Big data university (check http://www.spark.tc/) • Mesosphere • We deliver production-grade distro of spark on Mesos and DCOS Reactive Applications 7 “If I have seen further it is by standing on the shoulders of giants” Isaac Newton
- 8. The Team
- 9. The Team A dedicated team which • Contributes to the Spark project: add features, reviews PRs, test releases etc. • Supports customers deploying spark with online support, on-site trainings. • Promotes spark technology and/or our RP through talks and other activities. • Educates community with high quality courses. 9
- 11. The Project - Contributing • Where to start? https://cwiki.apache.org/confluence/display/SPARK/Contributing+to+Spar k Describes the steps to create a PR. • Tip: Bug fixes and specifically short fixes can be easier to contribute. Documentation update etc. • Things you need to understand as usual: • local development/test/debugging lifecycle • How about code style: https://github.com/databricks/scala-style-guide 11
- 12. The Project - Contributing... Tips about debugging: • Your IDE is your friend, especially with debugging. You could use SPARK_JAVA_OPTS with spark-shell SPARK_JAVA_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=y, address=5005" then remote debug your code. For driver pass the value to: --driver-java-options For executors pass the value to: spark.executor.extraJavaOptions (SparkConfig) • As long your IDE has the sources of the code under examination it could be only spark for example, then you can attach and debug that code only. 12
- 13. The project - A Software Engineering View •Most active Apache project. Spark is big. •Project size? A draft impression via… LOC (physical number of lines, CL + SLOC) weak metric but... •gives you an idea when you first jump into code •area size •you can derive comment density which leads to some interesting properties (Arafat, O.; Riehle, D.: The Comment Density of Open Source Software Code. IEEE ICSE 2009) •of course you need to consider complexity, ext libs etc when you actually start reading the code… 13
- 14. The project - A Software Engineering View Loc Spark: 601396 (scala/ java/ python) Loc metrics for some major components: spark/sql: 124898(Scala), 132028 (Java) spark/core: 114637 (Scala) spark/mllib: 70278 (Scala) spark/streaming: 25807 (Scala) spark/graphx: 7508 (Scala) 14
- 15. The Project - Contributing... Features: • Spark streaming backpressure for 1.5 (joint work with Databricks, SPARK-7398) • Add support for dynamic allocation in the Mesos coarse-grained scheduler (SPARK-6287) • Reactive Streams Receiver (SPARK-10420) on going work… Integration Tests: Created missing integration tests for mesos deployments: • https://github.com/typesafehub/mesos-spark-integration-tests Other: • Fixes • PR reviews • Voting (http://www.apache.org/foundation/voting.html) 15
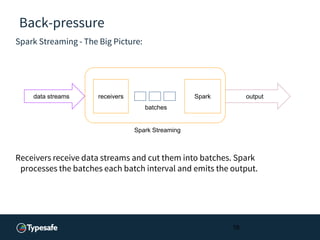
- 16. Back-pressure Spark Streaming - The Big Picture: Receivers receive data streams and cut them into batches. Spark processes the batches each batch interval and emits the output. 16 data streams receivers Spark output batches Spark Streaming
- 17. Back-pressure The problem: “Spark Streaming ingests data through receivers at the rate of the producer (or a user-configured rate limit). When the processing time for a batch is longer than the batch interval, the system is unstable, data queues up, exhaust resources and fails (with an OOM, for example).” 17 receiver Executor spark.streaming.receiver.maxRate (default infinite) number of records per second block generator blocks data stream Receiver Tracker block ids Spark Streaming Driver Job Generator Job Scheduler Spark Context Spark Driver runJob jobSet clock tick
- 18. Back-pressure Solution: For each batch completed estimate a new rate based on previous batch processing and scheduling delay. Propagate the estimated rate to the block generator (via ReceiverTracker) which has a RateLimiter (guava 13.0). Details: • We need to listen for batch completion • We need an algorithm to actually estimate the new limit. RateEstimator algorithm used: PID control https://en.wikipedia.org/wiki/PID_controller 18
- 19. Back-pressure - PID Controller K{p,i,d} are the coefficients. What to use for error signal: ingestion speed - processing speed. It can be shown scheduling delay is kept within a constant factor of the integral term. Assume processing rate did not change much between to calculations. Default coefficients: proportional 1.0, integral 0.2, derived 0.0 19
- 20. Back-pressure Results: • Backpressure prevents receiver’s buffer to overflow. • Allows to build end-to-end reactive applications. • Composability possible. 20
- 21. Dynamic Allocation The problem: Auto-scaling executors in Spark, already available in Yarn was missing for Mesos. The general model for cluster managers such as Yarn, Mesos: Application driver/scheduler uses the cluster to acquire resources and create executors to run its tasks. Each executor runs tasks. How many executors you need to run your tasks? I 21
- 22. Dynamic Allocation How Spark (essentially with an application side) requests executors? In Coarse-grained mode if dynamic allocation flag is enabled (spark.dynamicAllocation.enabled property) an instance of ExecutorAllocationManager (thread) is started from within SparkContext. Every 100 mills it checks the executors assigned for the current task load and adjusts the executors needed . 22
- 23. Dynamic Allocation The logic behind executor adjustment in ExecutorAllocationManager ... Calculate max number of executors needed: maxNeeded = (pending + running + tasksPerExecutor -1 )/ tasksPersExecutor numExecutorsTarget= Min (maxNeeded, spark.dynamicAllocation.executors) if (numExecutorsTarget < oldTargert) downscale If (scheduling delay timer expires) upscale is done Also check executor expire times to kill them. 23
- 24. Dynamic Allocation Connecting to the cluster manager: Executor number adjust logic calls sc.requestTotalExecutors which calls the corresponding method in CoarseGrainedSchedulerBackend ( Yarn, Mesos scheduler classes extend it ) which does the actual executor management. • What we did is provide the appropriate methods to Mesos CoarseGrainScheduler: def doKillExecutors(executorIds: Seq[String]) def doRequestTotalExecutors(requestedTotal: Int) 24
- 25. Dynamic Allocation In Yarn/Mesos you can call the following api to autoscale your app from your sparkcontext (supported only in coarse-grained mode): sc.requestExecutors sc.killExecutors But… “the mesos coarse grain scheduler only supports scaling down since it is already designed to run one executor per slave with the configured amount of resources.“ “...can scale back up to the same amount of executors” 25
- 26. Dynamic Allocation A smaller problem solved... Dynamic allocation needs an external shuffle service However, there is no reliable way to let the shuffle service clean up the shuffle data when the driver exits, since it may crash before it notifies the shuffle service and shuffle data will be cached forever. We need to implement a reliable way to detect driver termination and clean up shuffle data accordingly. SPARK-7820, SPARK-8873 26
- 27. Mesos Integration Tests Why? • This is joint work with Mesosphere. • Good software engineering practice. Coverage (nice to have)... • Prohibit mesos spark integration being broken. • Faster release for spark on mesos. • Give the spark developer the option to create a local mesos cluster to test his PR. Anyone can use it, check our repo. 27
- 28. Mesos Integration Tests • It is easy… just build your spark distro, checkout our repository … and execute ./run_tests.sh distro.tgz • Optimization on dev lifecycle is needed (still under development). • Consists of two parts: • Scripts to create the cluster • Test runner which runs the tests against the suite. 28
- 29. Mesos Integration Tests • Docker is the technology used to launch the cluster. • Supports DCOS and local mode. • Challenges we faced: • Docker in bridge mode (not supported: SPARK-11638 ) • Write meaningful tests with good assertions. • Currently the cluster integrates HDFS. We will integrate Zookeeper and Apache Hive as well. 29
- 30. More on Support
- 31. Customer Support • We provide SLAs for different needs eg. 24/7 production issues. • We offer on-site training / on-line support. • What customers want so far: •Training •On-site consulting / On-line support • What do customers ask in support cases? •Customers usually face problems learning the technology eg. how we start with Spark, but there are also more mature issues eg. large scale deployment problems. 31
- 32. Next Steps
- 33. RoadMap • What is coming... • Introduce Kerberos security - Challenge here is to deliver the whole thing authentication, authorization, encryption.. • Work with Mesosphere for Typesafe spark distro and the mesos spark code area. • Evaluate Tachyon. • Officially offer support to other spark libs (graphx, mllib) •ConductR integration •Spark notebook 33
- 34. ©Typesafe 2015 – All Rights Reserved