SLO DRIVEN DEVELOPMENT, ALON NATIV, Tomorrow.io
Download as PPTX, PDF•0 likes•68 views

The document discusses service level objectives (SLOs) and agreements (SLAs) focusing on system reliability and its impact on costs, velocity, and architecture. It emphasizes the importance of measurable data for improving reliability and lists various metrics and practices for achieving good SLOs, such as error budgets. Additionally, it highlights the trade-offs involved in budget management for maintaining high reliability standards.






















































































SLO DRIVEN DEVELOPMENT, ALON NATIV, Tomorrow.io
- 4. Name: Alon Nativ Company: Tomorrow.io Hobbies: Rant about Python @anativ /anativ
- 6. Accurate
- 7. Accurate ML & Data
- 8. Accurate ML & Data Save Lives
- 10. LIGHTNING ALERT
- 12. SIMPLE DESIGN
- 22. The most IMPORTANT feature of any system is its RELIABILITY
- 23. 100% is the wrong RELIABILITY target for basically EVERYTHING. Benjamin Trynor Sloss VP of 24x7 Engineering, Google
- 24. every number that you pick has DIRECT IMPACT on your cost velocity and architecture 99.5 99.4 99.6 99.7 99.8 99.9 1
- 26. SLA
- 27. SLA - Service Level Agreement
- 28. SLA - Service Level Agreement Binding Agreement
- 29. SLA - Service Level Agreement Binding Agreement Pay
- 30. SLA - Service Level Agreement Binding Agreement Pay Sales & Customers
- 31. DOWN OVER a DAY
- 33. SLA Refund Time / Month 99% > X >= 95% 25% 1d 12h 31m
- 34. If you are proud of your SLA you are probably doing something WRONG
- 35. SLA SLO
- 36. SLO - Service Level Objectives
- 37. SLO - Service Level Objectives User Happiness
- 38. SLO - Service Level Objectives User Happiness Your Expectations
- 39. SLO - Service Level Objectives User Happiness Your Expectations Product & SRE*
- 42. SLI - Service Level Indicator
- 43. SLI - Service Level Indicator Key Metrics
- 44. SLI - Service Level Indicator Key Metrics Monitors
- 45. SLI - Service Level Indicator Key Metrics Monitors Developers & SRE*
- 46. SLI = good events valid events X 100
- 48. GOOD SLI
- 49. GOOD SLI Up to 4 2-4
- 50. GOOD SLI Up to 4 No Internal* Metrics 2-4
- 52. Response Time
- 56. HIGH CORRELATION
- 58. This slide can’t be reached ERROR_NO_SLIDE_FOUND
- 59. 1 - SLO = ERROR BUDGET
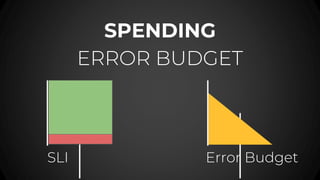
- 61. SPENDING ERROR BUDGET SLI Error Budget
- 62. SPENDING ERROR BUDGET SLI Error Budget
- 64. MetaGoat
- 65. Team A: TESTS Team B: CI/CD
- 66. W. Edwards Deming. Data Scientist Without DATA you are another person with an OPINION.
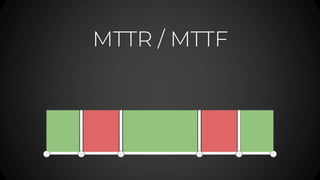
- 67. MTTR / MTTF
- 68. MTTR Mean Time To Recovery
- 69. MTTF Mean Time to Failure
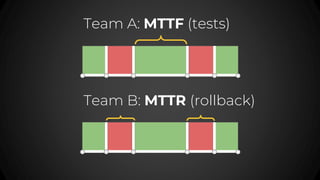
- 70. Team B: MTTR (rollback) Team A: MTTF (tests)
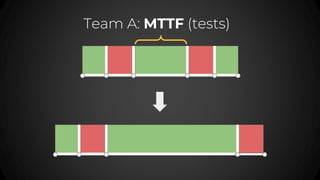
- 71. Team A: MTTF (tests)
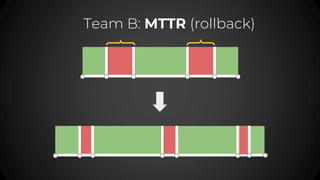
- 72. Team B: MTTR (rollback)
- 73. Team B: MTTR (rollback) Team A: MTTF (tests)
- 74. If you can’t MEASURE it, you can’t IMPROVE it. Lord Kelvin Mathematician & engineer
- 75. TRADEOFFS
- 76. SPARE BUDGET
- 79. SPARE BUDGET Features Risky Experiments Spot / preemptible
- 80. SPARE BUDGET Features Risky Experiments Spot / preemptible Scale Down
- 81. SPARE BUDGET Features Risky Experiments Spot / preemptible Scale Down A/B Testing
- 82. OUT OF BUDGET
- 84. OUT OF BUDGET Deployment freeze Post Mortem
- 85. OUT OF BUDGET Deployment freeze Post Mortem CI/CD
- 86. OUT OF BUDGET Deployment freeze Post Mortem CI/CD Monitoring
- 87. OUT OF BUDGET Deployment freeze Post Mortem CI/CD Monitoring Relax SLO
- 88. OUT OF BUDGET Deployment freeze Post Mortem CI/CD Monitoring Relax SLO Deprecate Services
- 89. HIGH SLO
- 91. HIGH SLO Less Budget Development Time
- 92. HIGH SLO Less Budget Development Time Sleeping Hours
- 93. HIGH SLO Less Budget Development Time Sleeping Hours Maintenance x2-x10
- 94. FIRST STEPS
- 95. USER CENTRIC
- 96. In GOD we trust all others bring DATA W. Edwards Deming. Data Scientist
- 97. USE YOUR BUDGET
- 99. If you can’t manage your RELIABILITY, your reliability MANAGES you
- 100. Be part of tomorrow, TODAY. alon@tomorrow.io /anativ
Editor's Notes
- #2: Hello <PAUSE> Today I’m going to talk about “SLO Driven Development” But before we will do that, I want to ask you a few questions Who knows here what is SLA [RAISE HAND] SLO? [PAUSE] SLI? [PAUSE] How heard about SLO Driven Development? [PAUSE] Ok, they are few people here that knows understand Japanese
- #3: Because, when I searched for “SLO Driven Development” I got two results <PAUSE> and well, it was Japanese There not a lot of people here that knows Japanese so we will do it in English. And I don’t even speak Japanese :)
- #4: What are we going to talk about today? Everyone wants a service that is up and reliable 100% of the time. But no one is able to do it. Do we really want it? Do we need it? Today I’ll talk about tools that can help us manage our reliability, improve our time to value, save money and make our team happier Improve time to value Save Money Make team happier
- #5: My name is Alon Nativ I work at Tomorrow.io as Systeem Architect Hobbies: Rant about Python You can listen to me talk at the reversim podcast Follow me on twitter / linkedin
- #6: Tomorrow.io is a weather intelligence platform. We provide companies weather insights in order to improve their business.
- #7: We are accurate weather forecast, minute by minute by the street level. So we can tell you that it is going to rain tomorrow at 12:17 here at the University for 21min but only 3min after that at sharona market.
- #8: We are using ML & big data, handling Billions of events per minute in order to do that.
- #9: But thing that I most proud of is that we alerts on weather hazards, lightning, and flood in order to save people life especially on 3rd world countries So reliability is very important to us.
- #10: I would like to start with a story of a system that we built, and talk about the Good the bad & the ugly [PAUSE] and it got really ugly This is a story about a developer that just wanted to get home alive but took some wrong turns in the middle of the process
- #11: Tomorrow.io is a weather company, so we wanted to build a lightning alert system called “Fulmo”. Fulmo is the esperanto word for lightning, esperanto is some flavor of latin. So what is this system: There are lightning sensors all over the world that collects information on lightning strike it can be Cloud to Cloud or Cloud to Ground and provides some information about the lightning. The location of the lightning - lat/lon If it was Cloud 2 Cloud or Cloud 2 Ground How many sensors saw it And a few more variables on the lightnings Now we have clients that wants to get a notifications when the lightning is in a specific area. The notification can be a WebHook, sms, email, slack you named it. So the clients define area of interests and some filters on it and they want to be notified once the conditions are met. It can be by the lightning type / by amount of lightnings in a few seconds, when there are no lightnings for a few minutes or some other parameters. [PAUSE] The next step [NEXT SLIDE] The developer took his notebook and wrote the requirements
- #12: The developer took his notebook and wrote the requirements The system requirements were very simple The PM asked one thing Notify on Every Lightning In Less Than 500 millisecond 1 liner Short and very easy to understand
- #14: So I looked at the design and I was very happy I thought to myself that we are building exactly the right system that will take us where we need to. We are building a very simple and efficient system. something that everyone likes [PAUSE] Someone even told me, this system is like bicycles, it is THE most efficient tool to get from point A to point B it is very easy to maintenance and even a kid can use it. But… it seems that we were wrong, we were actually building something else. [CLICK] We built something that was much more like a spaceship :) I found out that we were building something very complex that was very far from the original design… The lambda were replaced by docker over k8s The queue systems were replaced by redis queue It becomes a multi regional system - so we had to add de-dup system to make sure that we are not sending the same lightning twice… and much more changes…. Instead of simple serverless system… we got something that is extremely complex to deploy and managed And we were WAY off our original time estimations
- #15: So I looked at the design and I was very happy I thought to myself that we are building exactly the right system that will take us where we need to. We are building a very simple and efficient system. something that everyone likes [PAUSE] But… it seems that I was wrong, we were actually building something else. [CLICK] I found out that we were building something very complex that was very far from the original design… The lambda were replaced by docker over k8s The queue systems were replaced by redis queue It becomes a multi regional system - so we had to add de-dup system to make sure that we are not sending the same lightning twice… and much more changes…. Instead of simple serverless system… we got something that is extremely complex to deploy and managed And we were WAY off our original time estimations
- #16: So I asked the developer, WHY???? We had a working system a very simple one. WHY did you decided to change it? His answer was: It simply didn’t answer the requirements On some cases we had cold start on the lambda and it took a bit over 500 mili to send the notification And why replacing the pub/sub? it doesn't guarantee a sub second delivery SLA But who cares about this rare cases? So we looked back at the requirements
- #21: Notify on Every Lightning In Less Than 500 millisecond [CLICK]
- #22: Every equals 100% So we were building a spaceship just because we had wrong definitions of SLA! [PAUSE] So let’s talk about SLAs [PAUSE]
- #23: The most important feature of any system is its reliability! [PAUSE] If reliability is the most important feature then why not aiming for 100% reliability What does it mean to get to 100% reliability? [PAUSE] Let’s put a data center in space! In case a meteor is going to hit earth! We want 100% reliability right? Everyone understands that this is stupied and unreasonable but we keep saying that we want that the system will be up ALL THE TIME [PAUSE] do we? Maybe 99.999% is good enough? why not 99.99%? How do we define this? Who is responsible for defining the limits? [PAUSE]
- #24: 100% is the wrong reliability target for basically EVERYTHING [PAUSE] This was said by Benjamin Trynor - VP of 24x7 Engineering at Google And he is basically the father of SRE he invented the term and he created that group in Google, so I think that we can all agree that he some experience with large systems.. Now if we will look back at our product requirements “Notify on EVERY Lightning In Less Than 500 ms” We know that the requirement were wrong. We all understand that 100% is the wrong number [PAUSE] So what is the right number? Sadly there is no easy answer for that.
- #25: So what is the reliability target that we should aim for? there is no easy answer for that But what I can tell you is that [PAUSE] If you are really serious about your SLO [PAUSE] every number that you pick has direct impact on your cost / velocity and architecture The higher the reliability target the more time it will take you to built the system you will need a much more complected system. It will be more expensive
- #26: We have tools that can help us find the right number SLA, SLO, SLI
- #27: We have tools that can help us find the right number SLA, SLO, SLI
- #28: SLA - The agreement you with your clients or users “Binding Agreement” - With external users it might be a legal contract You may need to pay your users! - this is not a good business :) Defined by “Sales / Customers” For most cases, SLA is just a business number to tell your clients that you will make sure that they will get good service and if not, you are going to pay them back. [PAUSE]
- #29: SLA - The agreement you with your clients or users “Binding Agreement” - With external users it might be a legal contract You may need to pay your users! - this is not a good business :) Defined by “Sales / Customers” For most cases, SLA is just a business number to tell your clients that you will make sure that they will get good service and if not, you are going to pay them back. [PAUSE]
- #30: SLA - The agreement you with your clients or users “Binding Agreement” - With external users it might be a legal contract You may need to pay your users! - this is not a good business :) Defined by “Sales / Customers” For most cases, SLA is just a business number to tell your clients that you will make sure that they will get good service and if not, you are going to pay them back. [PAUSE]
- #31: SLA - The agreement you with your clients or users “Binding Agreement” - With external users it might be a legal contract You may need to pay your users! - this is not a good business :) Defined by “Sales / Customers” For most cases, SLA is just a business number to tell your clients that you will make sure that they will get good service and if not, you are going to pay them back. [PAUSE]
- #32: If I’ll tell you that I know about an Amazing service but only if it will down for over a day and a half you will get a significant refund. I guess most of you will be laughing and some of you will say that they will never use such a service.
- #33: But probably Most of you use this service :) AWS can be down for over a day and a half each month and you will get a partial refund
- #34: But probably Most of you use this service :) AWS can be down for over a day and a half each month and you will get a partial refund
- #35: Remmber this [PAUSE] IF YOU ARE PROUD OF YOUR SLA YOU ARE PROBABLY DOING SOMETHING WRONG [PAUSE] It is a pure business decision, if it is not blocking your sales then you should keep it as low as possible! Don’t try to be a hero or be innovative with your SLA, this is not the place to do it [PAUSE] There are some rare cases that this is a go to market strategy but on most cases… Keep it low.
- #36: We have tools that can help us find the right number SLA, SLO, SLI
- #37: SLOs - The objectives your team must hit to meet that agreement “User Happiness” What you expect from yourself - you should have higher expectations than what others expect from you. - here you can be proud of your service SRE + Product The SLO needs to be higher than your SLA, As we saw before, that shouldn’t be that hard But it can take time to define the right SLO because A good SLO is the point where
- #38: SLOs - The objectives your team must hit to meet that agreement “User Happiness” What you expect from yourself - you should have higher expectations than what others expect from you. - here you can be proud of your service SRE + Product The SLO needs to be higher than your SLA, As we saw before, that shouldn’t be that hard But it can take time to define the right SLO because A good SLO is the point where
- #39: SLOs - The objectives your team must hit to meet that agreement “User Happiness” What you expect from yourself - you should have higher expectations than what others expect from you. - here you can be proud of your service SRE + Product The SLO needs to be higher than your SLA, As we saw before, that shouldn’t be that hard But it can take time to define the right SLO because A good SLO is the point where
- #40: SLOs - The objectives your team must hit to meet that agreement “User Happiness” What you expect from yourself - you should have higher expectations than what others expect from you. - here you can be proud of your service SRE + Product The SLO needs to be higher than your SLA, As we saw before, that shouldn’t be that hard But it can take time to define the right SLO because A good SLO is the point where
- #41: What is a good SLO? A good SLO is the point where your users should be happy. What is a happy user? Well there is no easy answer for that. We do know it should be better even much better than our SLA. SLO is the point where your users are happy with your service Unless you have 1 user and you can ask him, if not what should we aim for? 95% of the users? 80%? 50%? That is a really hard question and the answer is that we don’t know. But we can try. That is why SLO are defined with Product Managers. There job is to understand the users so they should say what is the business impact of downtime. Can we tolerate 1h per month? 30min? 10min? Because we invest development time the higher the SLO is we need to find the tradeoff between business and development time. You need to remember that SLO is only for external services it also for internal services. So maybe the user of your services are sitting next to you You can ask them what happens if the service is down. Maybe they can change the algorithm a bit, add caching or change the cadence that they use your service in order to relax the problem. So you will be able to reduce your SLO. In order to define good SLO you have to understand your users. —- What is a good SLO? A good SLO is the point where your users should be happy. What is a happy user? That is a really hard question :) Unless you have only one user and you can ask him you need to find the point where downtime doesn’t heart the business too much. It depend on the kind of service and the industry. Due to the fact that SLO has business implications it is usually defined with the product managers
- #42: We have tools that can help us find the right number SLA, SLO, SLI
- #43: SLI - The real numbers on your performance (metrics) “Key Metrics” Monitors (how + what to measure?) SLI is defined by developers + SRE
- #44: SLI - The real numbers on your performance (metrics) “Key Metrics” Monitors (how + what to measure?) SLI is defined by developers + SRE
- #45: SLI - The real numbers on your performance (metrics) “Key Metrics” Monitors (how + what to measure?) SLI is defined by developers + SRE
- #46: SLI - The real numbers on your performance (metrics) “Key Metrics” Monitors (how + what to measure?) SLI is defined by developers + SRE
- #47: What is good events? That is the easy part If you have a website and we put a target that we want to render the page in under 100ms. So every request that is under 100ms with status code 200 is a GOOD EVENT But what is a valid event? STATUS CODE 200 UNDER 100 ms
- #48: It is not easy to pick good SLI Let’s talk about few tips in order to do that
- #49: As a rule of thumb you should have 2-4 metrics CPU is not interesting Do you care what is the CPU in google servers when you are doing a search? You care about latency & response time so you should find metrics related to them Pick a metric that measure user happiness
- #50: As a rule of thumb you should have 2-4 metrics CPU is not interesting Do you care what is the CPU in google servers when you are doing a search? You care about latency & response time so you should find metrics related to them Pick a metric that measure user happiness
- #51: As a rule of thumb you should have 2-4 metrics CPU is not interesting Do you care what is the CPU in google servers when you are doing a search? You care about latency & response time so you should find metrics related to them Pick a metric that measure user happiness
- #52: Google Search Example
- #53: We probably care about the response time
- #54: We expect to see lots of resluts
- #55: We are expect to find our results in the first 3 results - not in the 5th page
- #56: We as users don’t care what is the CPU of the services while searching
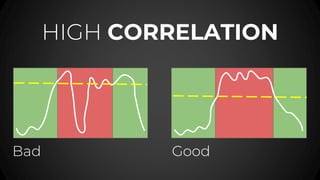
- #57: For example if your users are not happy in the red area then the left graph is not helping us *** Write notes from my recordings
- #58: For example if your users are not happy in the red area then the left graph is not helping us *** Write notes from my recordings
- #59: Let’s talk about errors. We already understand that our services are not 100% reliable so eventually everyone will have errors It can be partial downtime It can be planned or unplanned But how do we measure it? There is a simple way called error budget What is an error budget? The amount of time that you are allow to not provide service
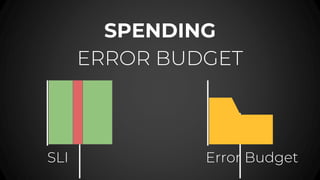
- #61: *Verify image Spending error budget First we need to change the term that we use when we have an error orr an outage. We are SPENDING error budget, not accidentally using it. You are in control of your own budget! You are the CFO of your own services This is your budget and you spend it. What should we SPEND our error budget on? So let’s see uber error budget spend pattern
- #62: The uber error rate graph, in the weekend they don’t have much errors… because no one is deploying to production, One of the drivers to high error rate is the number of your deployments… the more changes* that we make in the system the higher the chance that we will cause errors.
- #63: The uber error rate graph, in the weekend they don’t have much errors… because no one is deploying to production, One of the drivers to high error rate is the number of your deployments… the more changes* that we make in the system the higher the chance that we will cause errors.
- #64: The uber error rate graph, in the weekend they don’t have much errors… because no one is deploying to production, One of the drivers to high error rate is the number of your deployments… the more changes* that we make in the system the higher the chance that we will cause errors.
- #65: Let me tell you a story about MetaCat A company that build the Metaverse for cats Using VR they makes our cats happier, sleep better & the make sure that they are not going to take over the world! This company had 2 teams Each team had 4 downtimes per Month VP R&D told the team leaders to fix it Team A. made more tests Team B. worked on rollbacks What is a better approach? [PAUSE] Let’s See what you think Team A [RAISE HAND] OK Team B [RAISE HAND] Don’t know [RAISE HAND]
- #66: Let me tell you a story about MetaCat A company that build the Metaverse for cats Using VR they makes our cats happier, sleep better & the make sure that they are not going to take over the world! This company had 2 teams Each team had 4 downtimes per Month VP R&D told the team leaders to fix it Team A. made more tests Team B. worked on rollbacks What is a better approach? [PAUSE] Let’s See what you think Team A [RAISE HAND] OK Team B [RAISE HAND] Don’t know [RAISE HAND]
- #67: We are missing data to answer this Data is the key to make smart decisions Without data you are another person with an opinion
- #69: How to improve MTTR Faster rollback Gradual rollout Canary deployments Faster Ci/CD
- #70: How to improve MTTF Testing! Multi region Scale test
- #71: Team A: improved tests, they basically tried to improve the MTTF Team B: Improve the CI/CD to deploy code faster & do faster rollbacks
- #72: Team A: improved tests, they basically tried to improve the MTTF Team B: Improve the CI/CD to deploy code faster & do faster rollbacks
- #73: Team A: improved tests, they basically tried to improve the MTTF Team B: Improve the CI/CD to deploy code faster & do faster rollbacks
- #74: Team A: improved tests, they basically tried to improve the MTTF Team B: Improve the CI/CD to deploy code faster & do faster rollbacks
- #75: If you can’t measure it, you can’t improve it. So in order to improve quality we invest in tests or we can also invest in better rollback. Another option is to do a gradual rollout, so if we deploy to new version to 10% of our users even if we have outage of 30min - we will use only 3min of our error budget Improve SLI response Time Gradual Rollout - 10% of 60min
- #76: Now let’s talk about tradeoffs, how can we improve SLO by simply “stop writing code” / or more correctly “stop adding new features”, it might sound like a joke :) but let’s talk about a real world example when we actually want to do it. Let’s think that we want to move our servers to a new cloud or do a DB migration, 1 weeks of development? 2 weeks? 4M for 6m? Maybe we can deploy with downtime? And to recover it, not adding new features… work on test, other systems but you saved few weeks and used this time to do something else Maintenance window
- #77: What to do with the budget? Releasing new features Expected System Changes Inevitable failure in hardware, networks, etc.. Cloud issue Risky Experiments Save $ using spot / preemptible VM Spare Budget? You can use spot / preemptible machines Scale down Faster A/B testing
- #78: What to do with the budget? Releasing new features Expected System Changes Inevitable failure in hardware, networks, etc.. Cloud issue Risky Experiments Save $ using spot / preemptible VM Spare Budget? You can use spot / preemptible machines Scale down Faster A/B testing
- #79: What to do with the budget? Releasing new features Expected System Changes Inevitable failure in hardware, networks, etc.. Cloud issue Risky Experiments Save $ using spot / preemptible VM Spare Budget? You can use spot / preemptible machines Scale down Faster A/B testing
- #80: What to do with the budget? Releasing new features Expected System Changes Inevitable failure in hardware, networks, etc.. Cloud issue Risky Experiments Save $ using spot / preemptible VM Spare Budget? You can use spot / preemptible machines Scale down Faster A/B testing
- #81: What to do with the budget? Releasing new features Expected System Changes Inevitable failure in hardware, networks, etc.. Cloud issue Risky Experiments Save $ using spot / preemptible VM Spare Budget? You can use spot / preemptible machines Scale down Faster A/B testing
- #82: What to do with the budget? Releasing new features Expected System Changes Inevitable failure in hardware, networks, etc.. Cloud issue Risky Experiments Save $ using spot / preemptible VM Spare Budget? You can use spot / preemptible machines Scale down Faster A/B testing
- #83: Freeze feature releases Prioritize post mortem items Automate deployment pipelines Speed up your CI/CD Create internal dev tools Improve monitoring and observability Require SRE consultation Relax the SLO Kill the service!!!!
- #84: Freeze feature releases Prioritize post mortem items Automate deployment pipelines Speed up your CI/CD Create internal dev tools Improve monitoring and observability Require SRE consultation Relax the SLO Kill the service!!!!
- #85: Freeze feature releases Prioritize post mortem items Automate deployment pipelines Speed up your CI/CD Create internal dev tools Improve monitoring and observability Require SRE consultation Relax the SLO Kill the service!!!!
- #86: Freeze feature releases Prioritize post mortem items Automate deployment pipelines Speed up your CI/CD Create internal dev tools Improve monitoring and observability Require SRE consultation Relax the SLO Kill the service!!!!
- #87: Freeze feature releases Prioritize post mortem items Automate deployment pipelines Speed up your CI/CD Create internal dev tools Improve monitoring and observability Require SRE consultation Relax the SLO Kill the service!!!!
- #88: Freeze feature releases Prioritize post mortem items Automate deployment pipelines Speed up your CI/CD Create internal dev tools Improve monitoring and observability Require SRE consultation Relax the SLO Kill the service!!!!
- #89: Freeze feature releases Prioritize post mortem items Automate deployment pipelines Speed up your CI/CD Create internal dev tools Improve monitoring and observability Require SRE consultation Relax the SLO Kill the service!!!!
- #90: High SLO - the impact on system lifecycle higher Error rate Higher development time Higher maintenance time Less sleeping hours :) Maintenance a system cost ~2-10x development time the higher the SLO the more expensive that the system is
- #91: High SLO - the impact on system lifecycle higher Error rate Higher development time Higher maintenance time Less sleeping hours :) Maintenance a system cost ~2-10x development time the higher the SLO the more expensive that the system is
- #92: High SLO - the impact on system lifecycle higher Error rate Higher development time Higher maintenance time Less sleeping hours :) Maintenance a system cost ~2-10x development time the higher the SLO the more expensive that the system is
- #93: High SLO - the impact on system lifecycle higher Error rate Higher development time Higher maintenance time Less sleeping hours :) Maintenance a system cost ~2-10x development time the higher the SLO the more expensive that the system is
- #94: High SLO - the impact on system lifecycle higher Error rate Higher development time Higher maintenance time Less sleeping hours :) Maintenance a system cost ~2-10x development time the higher the SLO the more expensive that the system is
- #95: SLO not only for development but also to define teams Let’s look at google SRE group % toil should be 10-40% if over 40% they offload tasks to the developers or they need more people in the team At some point they stop feature releases
- #96: summarize Define your SLO Measure your error rate Make sure you are match your SLO That's it… Easy! :)
- #97: Think about your audience, your users What they really care about, what define happy user?
- #98: Data Data Data Without data we can’t make smart decisions.
- #99: Use your error budget! You probably don’t have a lot of it, but every budget can help you Don’t left money on the table
- #100: To summarize this Think about your users Use Data Use your error budget
- #101: We are software engineers, We are not building bridges We shouldn’t aim for 100% reliability and we must accept downtimes. Don’t hope that you won’t have downtimes, understand that you will have it. Don’t ignore the problem make sure that you manage it and don’t let it manage you