Démystifions le machine learning avec spark par David Martin pour le Salon Big Data Paris 2016
3 j'aime•4,796 vues

Le document présente une introduction au machine learning, en expliquant ses principes, ses paradigmes et les différents algorithmes appliqués. Il met également en avant l'outil Apache Spark comme une solution performante pour le traitement des données massives, avec des capacités d'apprentissage automatique variées. Enfin, il souligne l'importance de bien préparer les données et de sélectionner les algorithmes adéquats pour assurer des prédictions fiables.





























Démystifions le machine learning avec spark par David Martin pour le Salon Big Data Paris 2016
- 1. Démystifions le Machine Learning avec Spark
- 2. David MARTIN DIRECTEUR DU CONSEIL dmartin@ippon.fr @_dmartin_
- 3. Simple facts 90% de la donnée mondialeactuelle générée au cours des 2 dernières années
- 5. Définition Le Machine Learning est une branche de l’Intelligence Artificielle… … qui s’attache à étudier les techniques permettant à un système d’apprendre à réaliser des tâches. Souvent couplé au Data Mining, l’ensemble permet d’apporter une réponse complète aux problématiques d’analyse et de traitement de la donnée. Machine Learning paradigm == Programming by example
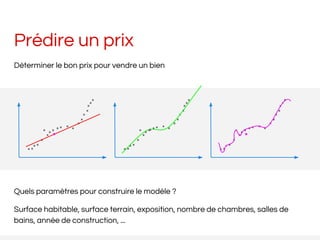
- 7. Prédire un prix Déterminer le bon prix pour vendre un bien Quels paramètres pour construire le modèle ? Surface habitable, surface terrain, exposition, nombre de chambres, salles de bains, année de construction, ...
- 8. Catégorisation d’entités Déterminer si un équipement présente un risque de panne Quels paramètres ? Nb heures de fonctionnement, température(s), régime, nombre total d’opérations, contraintes, ...
- 9. Création de groupes de données Grouper les données : segmenter une base clients Apprentissage non supervisé : l’algorithme n’a pas reçu d’information d’ appartenance à une catégorie, il crée lui même les groupes
- 10. Reconnaissance d’objets Reconnaître un objet, une forme, une lettre, un son, ...
- 11. Mais aussi... > Optimisations de campagnes marketing > Détection de fraude > Optimisations de chaines d’approvisionnement > Sécurisation de la fidélité client (customer churn prediction) > Moteurs de recommandation > Publicité ou Contenu ciblés > Nouveaux services disruptifs ...
- 13. Catégories d’algorithmes Catégories d’algorithmes d’apprentissage : > Apprentissage supervisé > Apprentissage non supervisé > Apprentissage semi supervisé > Apprentissage par renforcement ...
- 14. Principaux algorithmes Des algorithmes ou familles fréquemment utilisé(e)s : > Logistic regression > Linear regression > Support Vector Machine > Decision Tree / Random Forest > K-Means > (Deep) Neural networks ...
- 15. De la donnée brute à la prédiction
- 16. La donnée brute Au départ, beaucoup de données… … potentiellement issues de beaucoup de systèmes … traitant d’aspects divers De la donnée brute, encore impropre à la consommation
- 17. La préparation Nettoyer, Filtrer, Harmoniser les informations pour commencer à travailler > Supprimer ou compléter les données incomplètes > Retenir les données relatives au domaine ciblé > Homogénéiser les formats, les valeurs (si issues de systèmes différents…) > Qualifier si besoin les informations (cas de l’apprentissage supervisé) > Dériver les informations de la masse existante
- 18. Identifier le cas d’utilisation Identifier la catégorie du cas d’utilisation pour identifier le ou les algorithmes potentiellement adaptés et sélectionner les paramètres en entrée offrant la meilleure pertinence Le bon choix d’algorithme(s) importe tout autant que la bonne identification et préparation des paramètres d’entrée
- 19. Implémenter, ajuster, itérer > Construire un modèle de prédiction sur la base d’une partie des données préparées > Tester le modèle > Déduire les ajustements nécessaires > Réitérer cette étape si besoin Le processus est itératif… … et peut prendre un temps important avant de donner satisfaction
- 20. Prédire ! Prédire reste la finalité Mais le modèle peut/doit vivre. Les postulats initiaux évoluent. Il doit être regénéré sur la base de données actualisées > A/B Testing > Sauvegarde et versioning des modèles
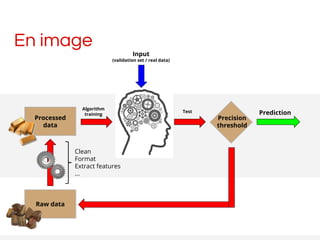
- 21. En image Raw data Processed data Clean Format Extract features ... Algorithm training Test Precision threshold Prediction Input (validation set / real data)
- 22. En synthèse Les points importants : > Disposer de beaucoup de données : le plus le mieux très souvent (mais pas toujours) > Pertinence et nombre des paramètres > Commencer simple et itérer (!= optimisation précoce)
- 23. De la théorie à la pratique
- 24. Implémentations Rappels On n’implémente pas sa version d’un algorithme On utilise une implémentation existante, testée et éprouvée
- 25. Approches et outils Approche SaaS > API spécialisées ou génériques > Azure Machine Learning > Amazon Machine Learning > Google Prediction API ... Approche “tailor made” (plus bas niveau) > Pandas / Scikit Learn > Vowpal Wabbit > Weka > Apache Spark ...
- 26. Apache Spark Apache Spark en quelques points > Projet de l’Université de Berkeley (2009) > Solution générique et performante de traitement de données > Adaptée aux très gros volumes de données > Distribue les traitements > Données en mémoire pour une meilleure performance > Ecrit en Scala, bindings Java, Python et R > Traction de plus en plus forte
- 27. Apache Spark Spark offre une solution performante de traitements de la donnée
- 28. Spark ML / ML Lib Principaux algorithmes supportés > Classification et régression ○ Linear regression, logistic regression, SVM ○ Naive Bayes (classification) ○ Decision Trees (Random Forest, Gradient-Boosted Trees) > Système de recommandation ○ Collaborative Filtering (Alternating Least Squares) > Clustering ○ K-Means, Latent Dirichlet allocation, … > Frequent Pattern Mining > Facilités pour la réduction de dimension (SVD, PCA) > Optimisations possibles (Stochastic Gradient Descent…) > Organisation des traitements sous forme de Pipelines (Spark ML)
- 29. External libraries / Extensions Spark peut être étendu : > librairies additionnelles tirant profit du framework > Time Series > Deep Learning > Graph (GraphFrame) et profiter de solutions externes : > Notebooks (Zeppelin, Databricks, …) > Solutions de dashboards (Databricks Dashboards)
- 30. Pour conclure Apache Spark est une solution polyvalente et en pleine croissance ⇒ Pertinence de la plateforme à l’ ère du Big Data Les perspectives futures sont très intéressantes : ● Evolution constante de la bibliothèque d’algorithmes, ● librairies externes complémentaires spécialisées, ● traction en forte accélération, ...
- 31. Venez nous rendre visite au STAND IPPON 501 PARIS - BORDEAUX - NANTES WASHINGTON DC - NEW-YORK - RICHMOND contact@ippon.fr www.ippon.fr - www.ippon-hosting.com - www.ippon-digital.fr @ippontech - 01 46 12 48 48